 2024-08-27
2024-08-27 阅读:2325
阅读:2325 来源:曲速超为
来源:曲速超为8月27日,一年一度的Hotchips在美国隆重举行。
作为一个被集成电路行业人员所熟知的盛会,全称为A Symposium on High Performance Chips的Hotchips于每年八月份在斯坦福大学举行。不同于其他行业会议以学术研究为主,HotChips是一场产业界的盛会,各大处理器公司会在每年的会上展现他们最新的产品以及在研的产品。
综合了第一天亮相的芯片公司的重点,让大家了解一下前沿动态。
NVIDIA Blackwell 备受关注
可以肯定的是,NVIDIA Blackwell 将在 2025 年大卖。该公司在 Hot Chips 2024 上更深入地介绍了平台架构。Blackwell 是业内许多人都兴奋的东西。NVIDIA 这次谈论的不是单个 GPU,而是 AI 集群级别。这很有意义,特别是如果你看到来自大型 AI 商店的演讲,例如 OpenAI 在 Hot Chips 2024 上关于构建可扩展 AI 基础设施的主题演讲。

NVIDIA 不仅注重构建硬件集群,还注重构建具有优化库的软件。

NVIDIA Blackwell 平台涵盖从 CPU 和 GPU 计算到用于互连的不同类型的网络。这是从芯片到机架和互连,而不仅仅是 GPU。

我们在今年早些时候的NVIDIA GTC 2024 主题演讲中对 Blackwell 进行了相当深入的研究。

GPU 非常庞大。其中一个重要功能是与 Grace CPU 连接的 NVLink-C2C。

作为NVIDIA最新的GPU,也是其性能最高的GPU。

NVIDIA 使用 NVIDIA 高带宽接口 (NV-HBI) 在两个 GPU 芯片之间提供 10TB/s 的带宽。

NVIDIA GB200 Superchip 是半宽平台中的 NVIDIA Grace CPU 和两个 NVIDIA Blackwell GPU。两个并排意味着每个计算托盘有四个 GPU 和两个 Arm CPU。

NVIDIA 拥有新的 FP4 和 FP6 精度。降低计算精度是提高性能的众所周知的方法。
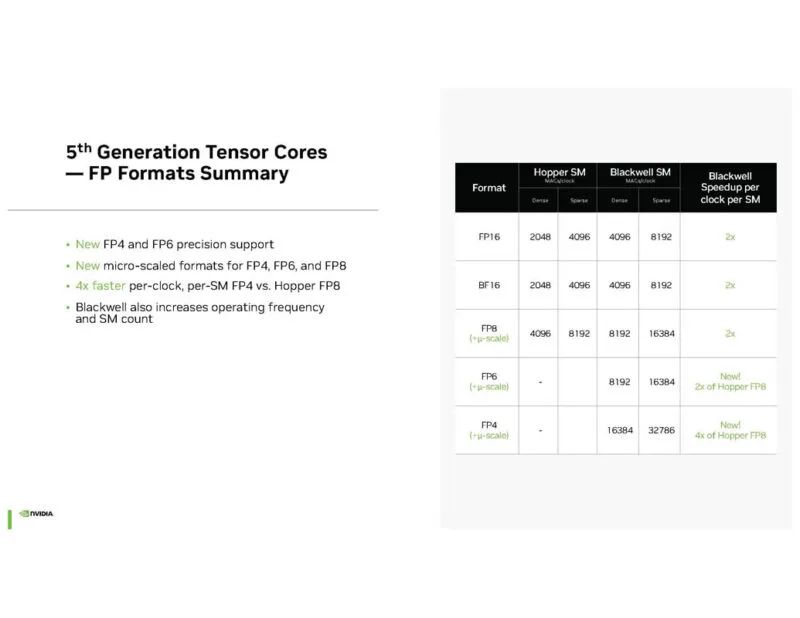
NVIDIA Quasar 量化用于确定可以使用较低精度的内容,从而减少计算和存储。
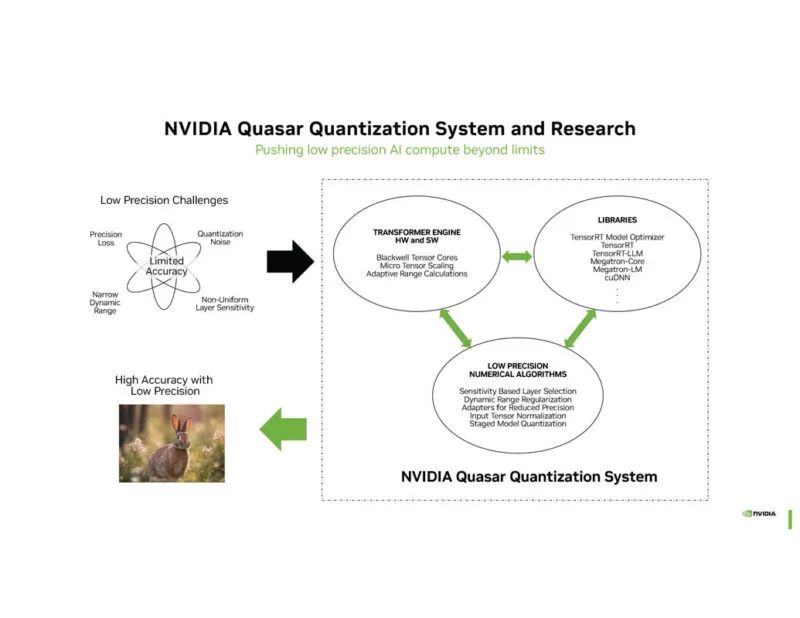
NVIDIA 表示,用于推理的 FP4 在某些情况下可以接近 BF16 的性能。

这是使用 FP16 推理和 FP4 的图像生成任务。这些兔子并不相同,但乍一看它们相当相似。

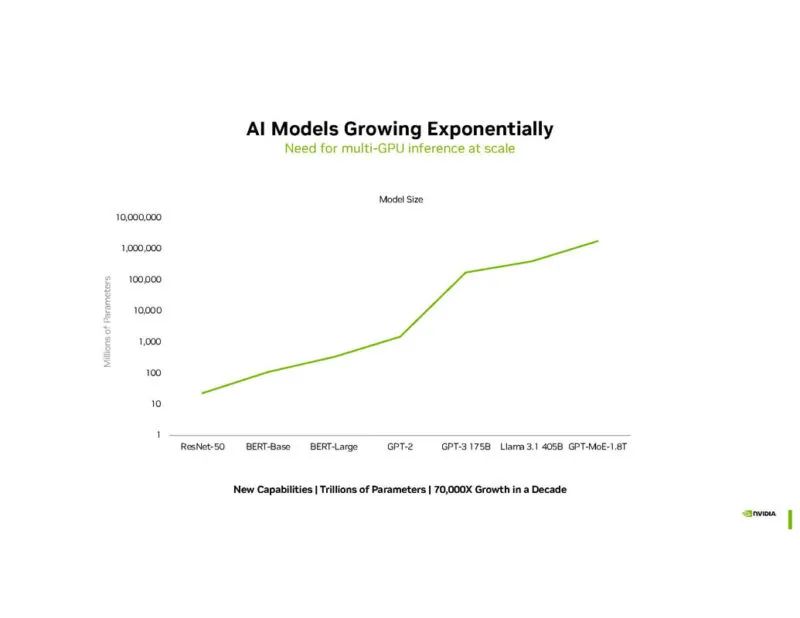
NVIDIA 表示 AI 模型正在不断发展。
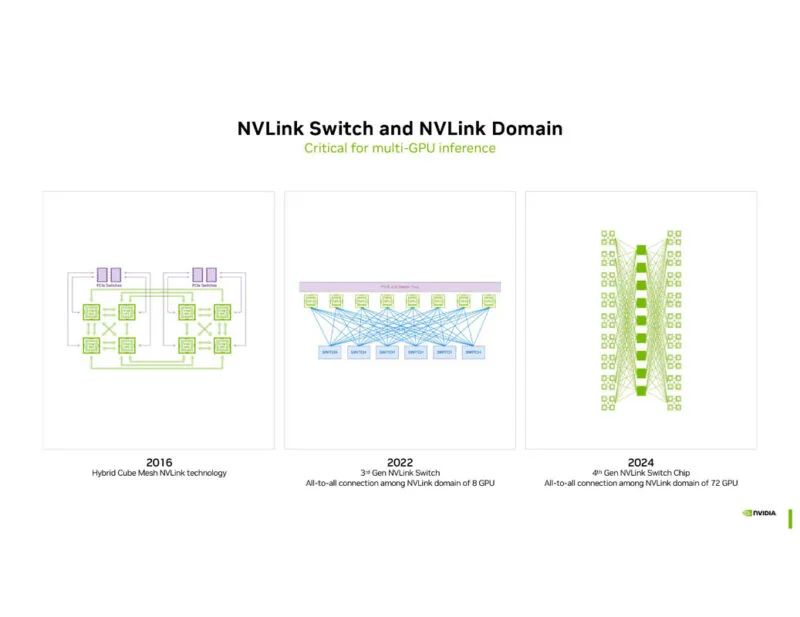
PHY 之所以变得非常重要,是因为 NVIDIA 的秘密武器之一就是能够通过 NVLink 比其他技术更高效地在系统的不同部分传输数据。

NVLink 交换芯片和 NVLink 交换tray旨在以比简单地使用以太网等现成解决方案更低的功率推送大量数据。

NVLink从 2016 年的 8 个 GPU 开始,到目前这一代的 72 个 GPU 都 实现了 这个目标。巧合的是, Hot Chips 30大会上关于 16-GPU NVSwitch DGX-2 拓扑的 NVIDIA NVSwitch 细节没有被提及。
NVIDIA 展示了 GB200 NVL72和 NVL36。NVL36 是 36 GPU 版本,适用于无法处理 120kW 机架的数据中心。
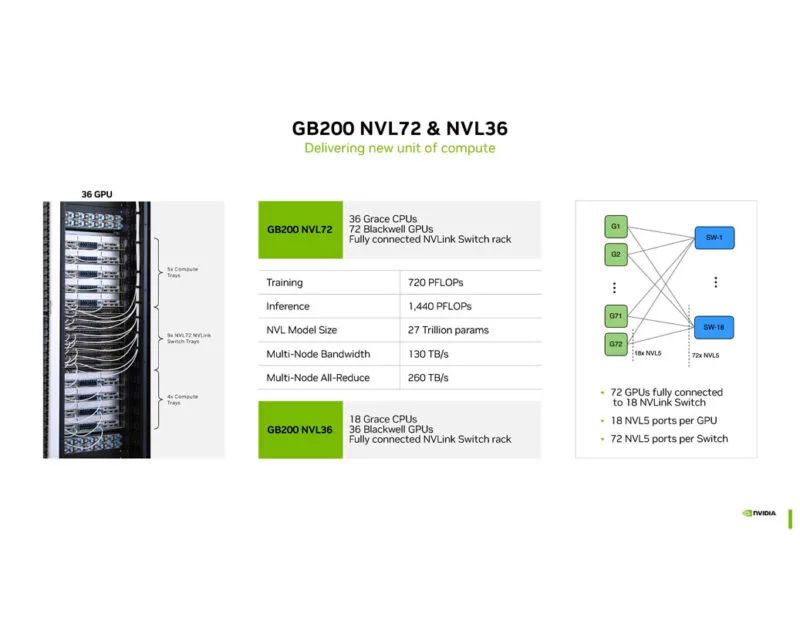
Spectrum-X、 Spectrum-4(类似于 Marvell Teralynx 10 51.2T 以太网交换机)加上 BlueField-3为以太网上的 RDMA 网络提供了组合解决方案。从某种意义上说,NVIDIA 已经在做一些 UltraEthernet 联盟将在未来几代中引入的事情。

GB200 NVL72是为万亿参数AI设计的。
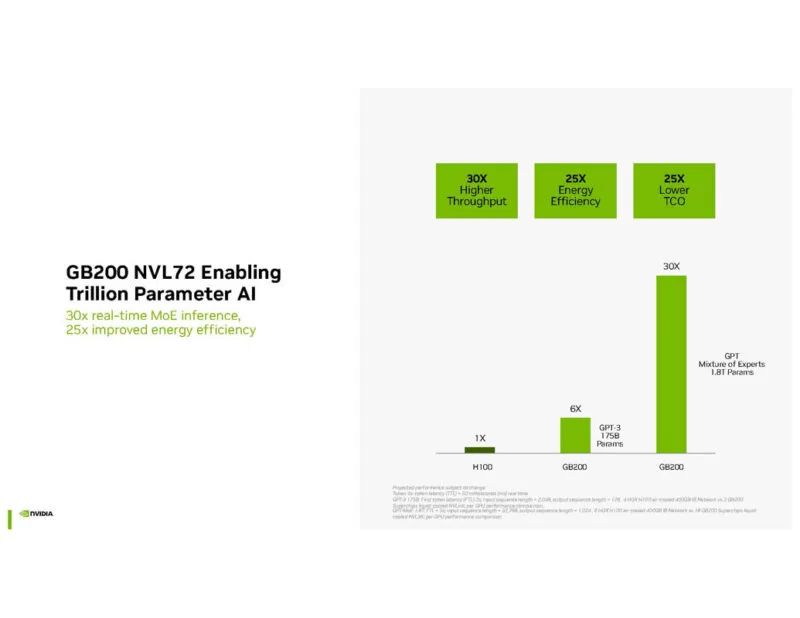
随着模型尺寸的增加,在多个 GPU 之间分配工作负载势在必行。
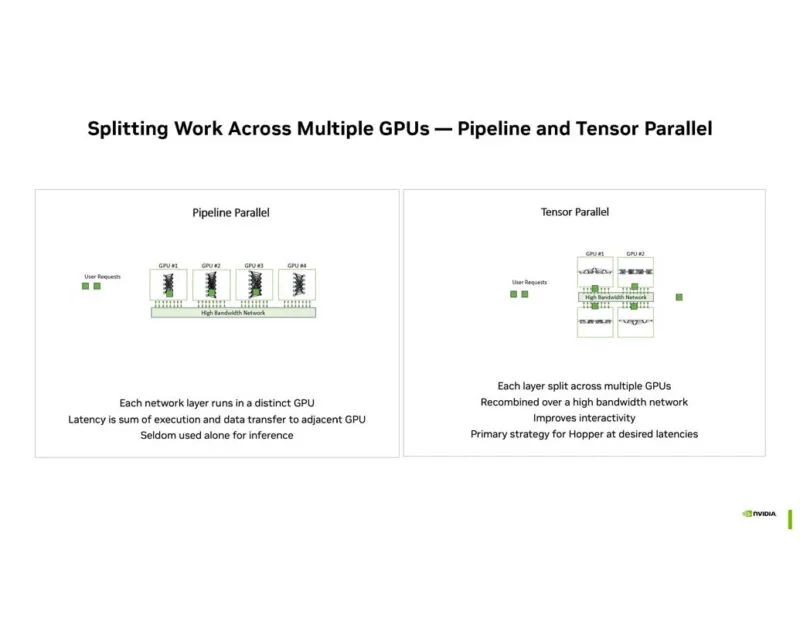
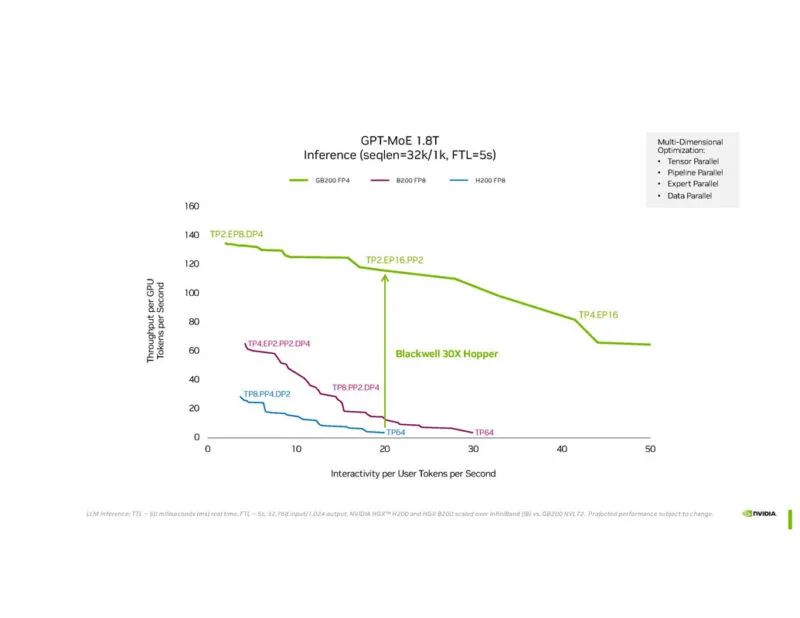
Blackwell 足够大,可以在一个 GPU 中处理专家模型。

NVIDIA 正在展示 GPT-MoE 1.8T 的性能。
这是新的 NVIDIA 路线图幻灯片。2026 年将推出 1.6T ConnectX-9,这意味着 NVIDIA 似乎指出了对 PCIe Gen7 的需求,因为 PCIe Gen6 x16 无法处理 1.6T 网络连接。也许可以使用多主机,但这令人兴奋。

以下是简要摘要:

除了路线图幻灯片外,我们之前已经看到过很多这样的内容。有趣的是,我们参加的会议中有很多 AI 加速器。与此同时,NVIDIA 不仅在构建集群,还在优化一切,包括互连、交换机芯片,甚至部署模型。AI 初创公司面临的一个挑战是,NVIDIA 不仅在制造当今的芯片、交换机、NIC 等。相反,它正在进行前沿研究,以便其下一代产品能够在集群级别满足未来模型的需求。这是一个很大的不同。
Jim Keller公司最新芯片细节
芯片工程师Jim Keller因其过往丰富的履历备受关注,其担任CEO的Tenstorrent 在 Hot Chips 2024 上展示了更多关于其 Blackhole 芯片的信息。据介绍,Blackhole 是Tenstorrent 的下一代独立 AI 计算机,将配备该公司的 140 个 Tensix++ 核心、16 个 CPU 核心和一系列高速连接。Blackhole 将提供高达 790 TOPS 的计算性能(使用 FP8 数据类型)。
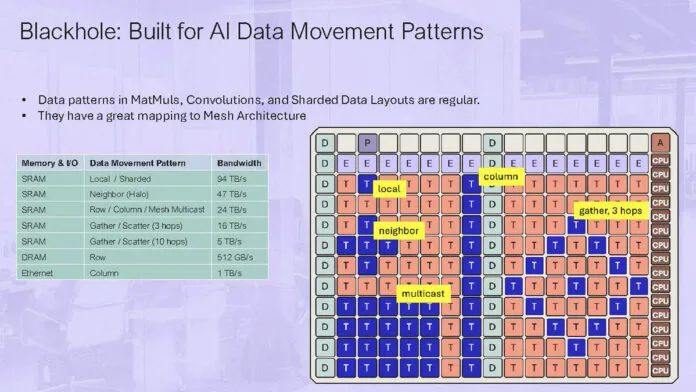
这是 Tenstorrent AI Silicon 路线图。Blackhole 是 2023 年及以后的芯片,是对上一代 Grayskull 和 Wormhole 的重大更新。
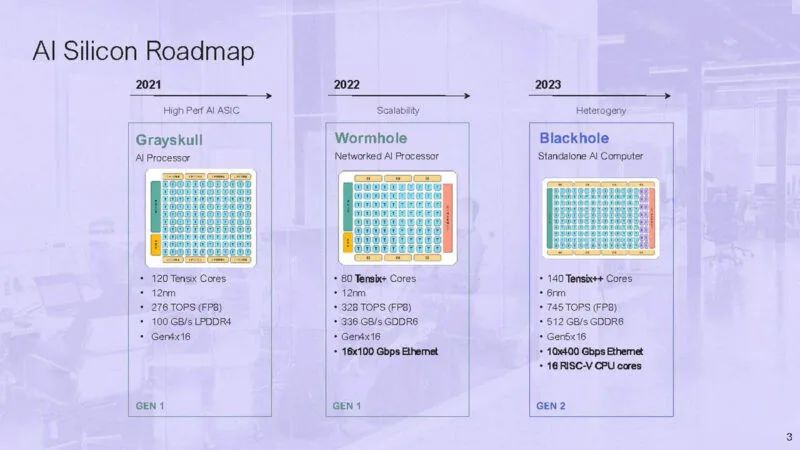
Blackhole 是一台基于以太网的独立人工智能计算机。
16 个 RISC-V 核心分为 4 个集群,每个集群有 4 个。Tensix 核心位于中间,以太网位于顶部。

该芯片具有 10x 400Gbps 以太网和 512GB/s 的带宽。
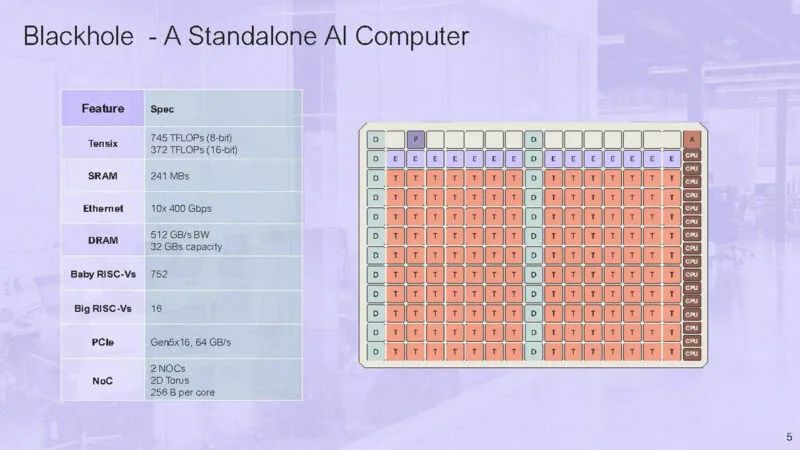
16 个大型 RSIC-V 内核可以运行 Linux。其余 752 个 RISC-V 内核被称为“小型”内核,可使用 C 内核进行编程,但不能运行 Linux。
小型 RISC-V 是可编程的,用于计算、移动数据和存储。
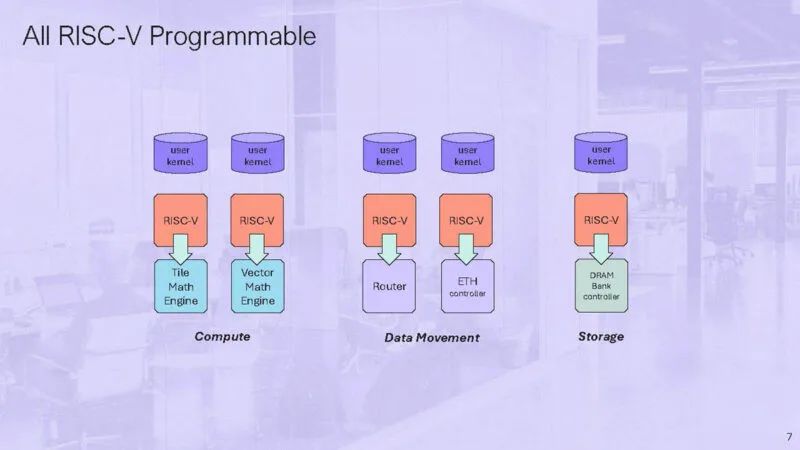
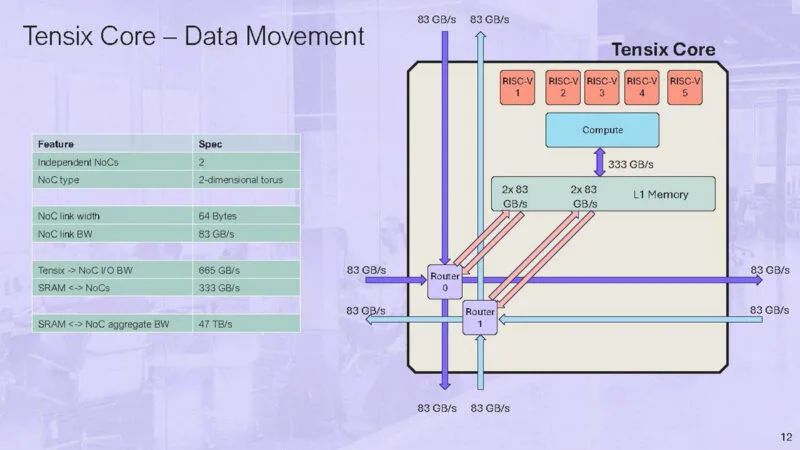
这是带有 5 个小型 RISC-V 的 Tensix 核心的示意图。
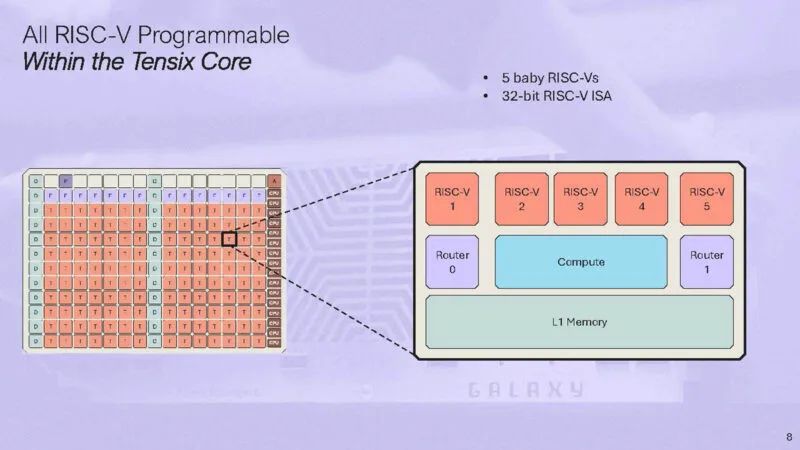
还有两个路由器连接到 NOC。
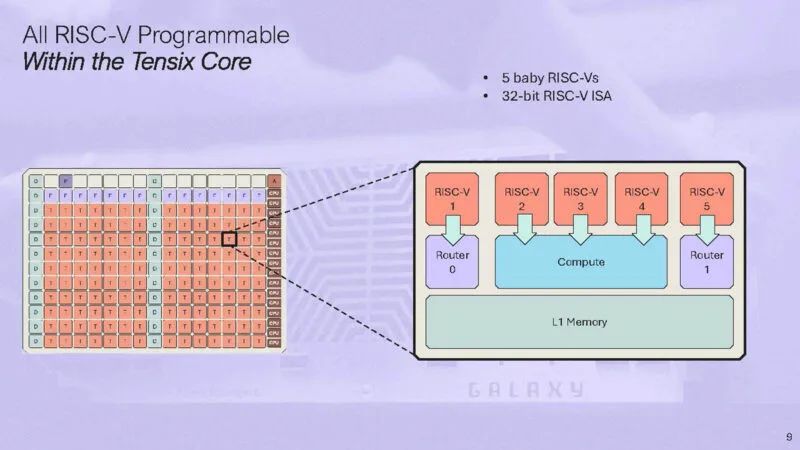
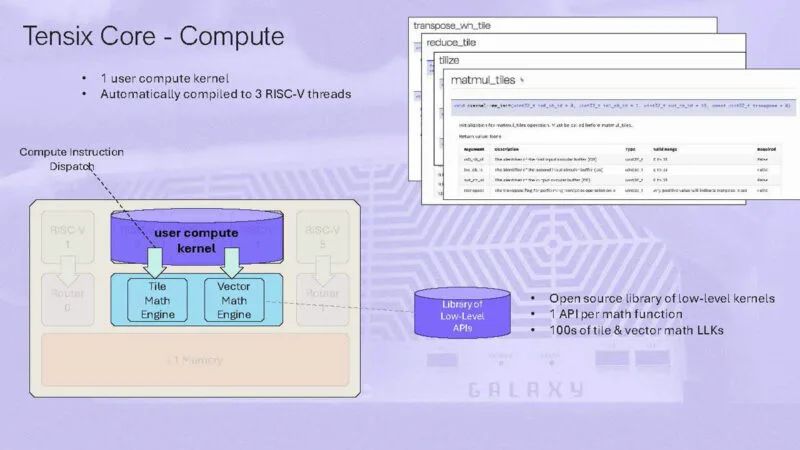
用户可以在每个 Tensix 核心上编写一个计算内核和两个数据移动内核。
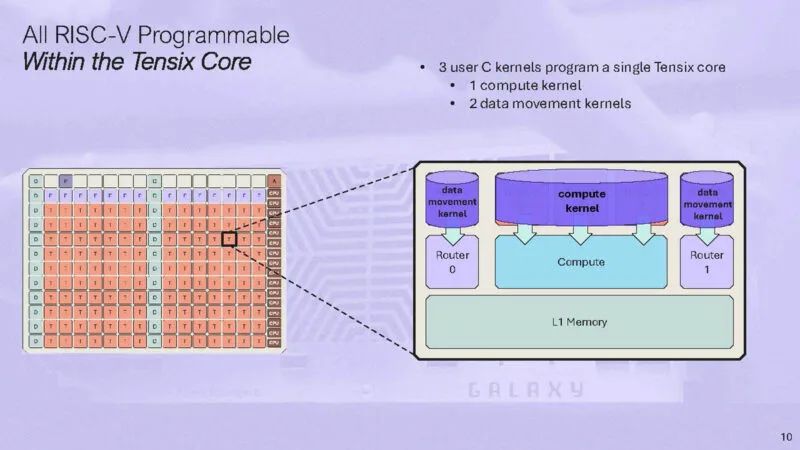
以下是有关数据移动内核的更多信息。
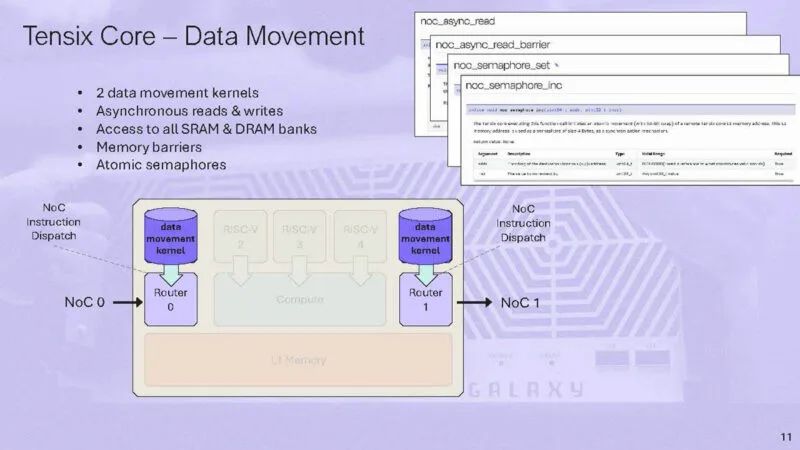
放大路由。NOC 是静态调度的。路由器向上和向左或向下和向右移动。
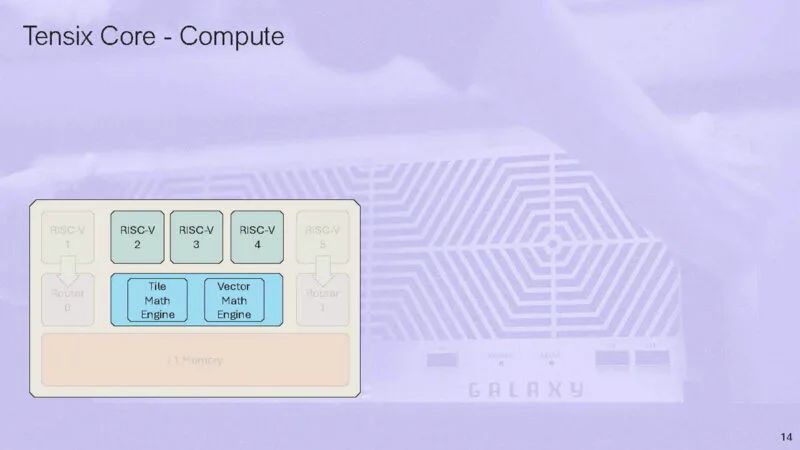
根据需要,核心可用于执行简单或复杂的操作。
在计算引擎上,有一个图块数学引擎和一个矢量数学引擎。
Tile 引擎在 32×32 的图块上运行。
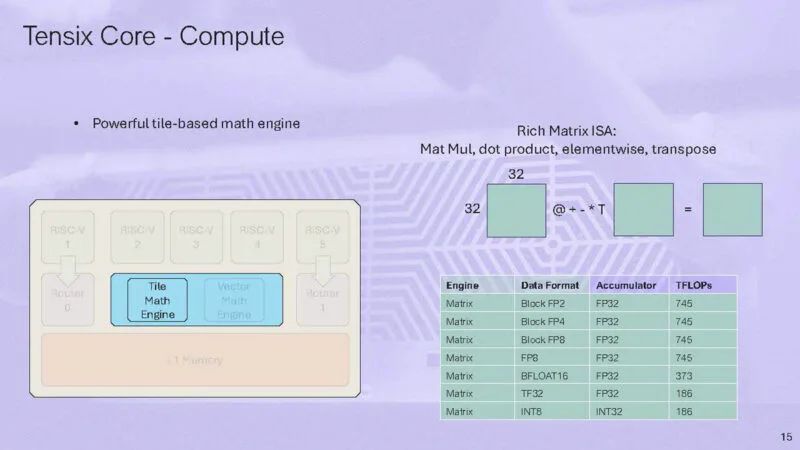
以下是有关矢量数学引擎的更多信息:
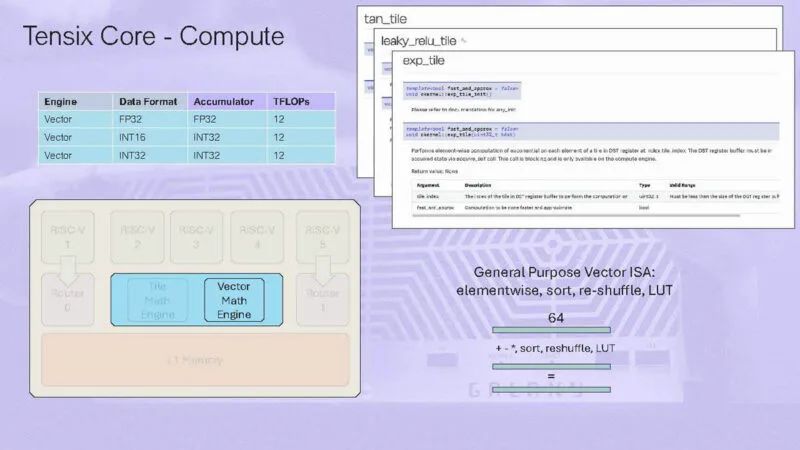
一个用户计算内核自动编译为3个RISC-V线程。
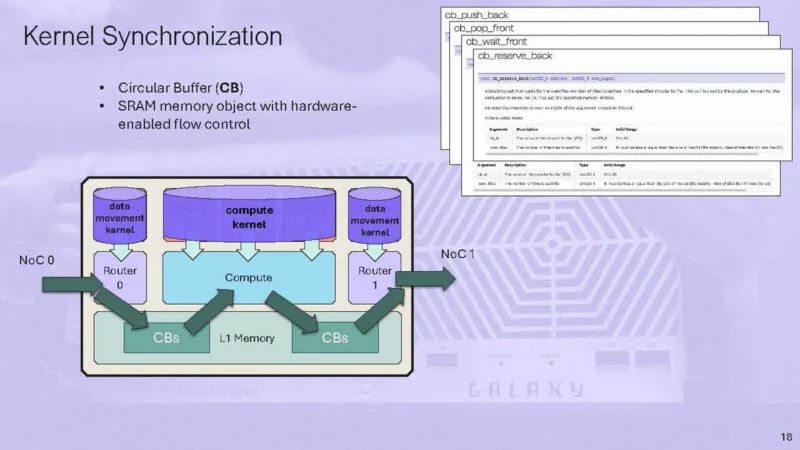
这是内核同步,有硬件启用的流控制来帮助同步内核。
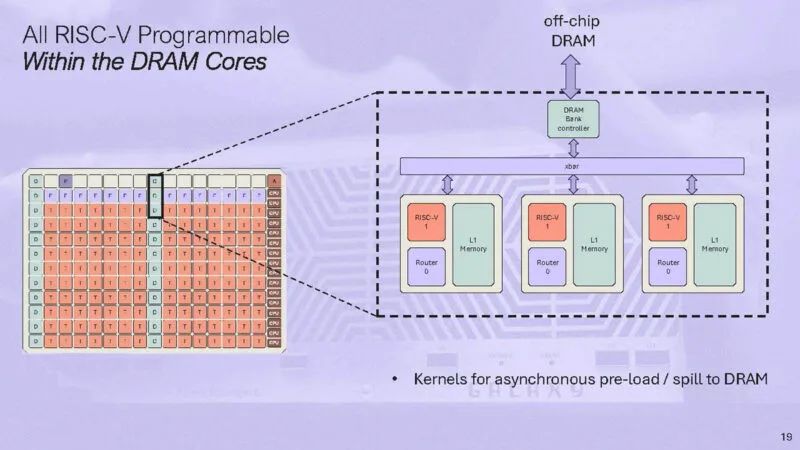
这是要移至片外 DRAM 的内存。但总体而言,我们的想法是尽可能将数据保留在本地和 SRAM 中,而不是使用外部 DRAM。
以太网在 Tenstorrent 架构中非常重要。
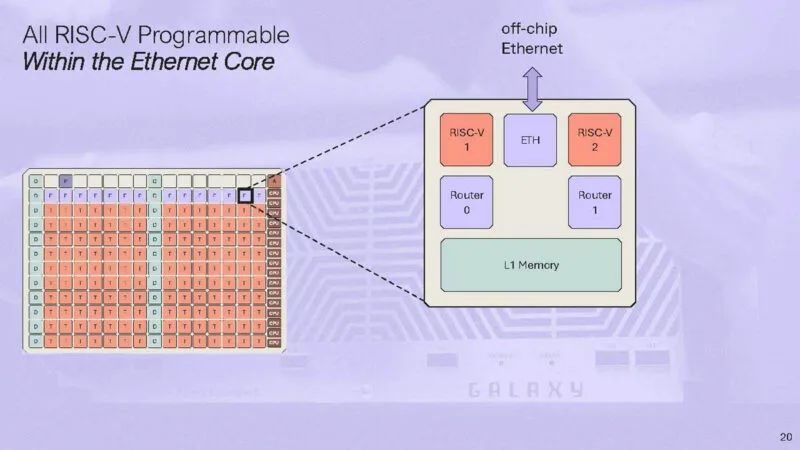
其中一个关键想法是 Blackhole 将使用以太网进行扩展。以太网的优势在于定期进行性能更新,业内几乎每个人都在某种架构层面使用它。这就是 Tenstorrent 无需设计 NVLink 或 InfiniBand 之类的东西就能实现大量扩展的原因。
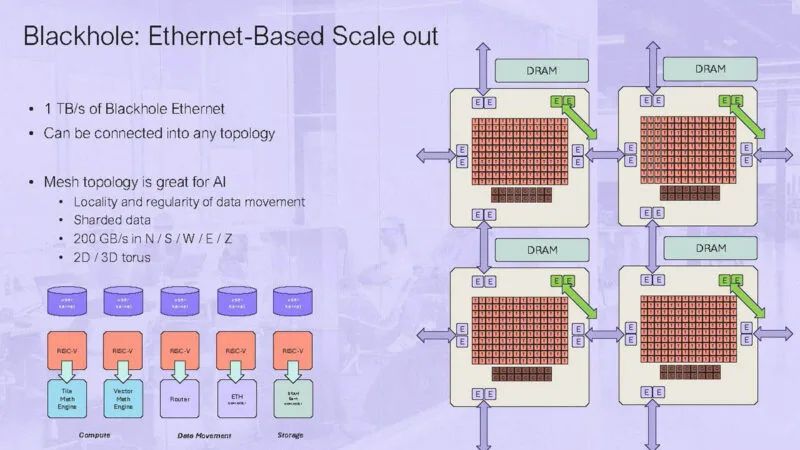
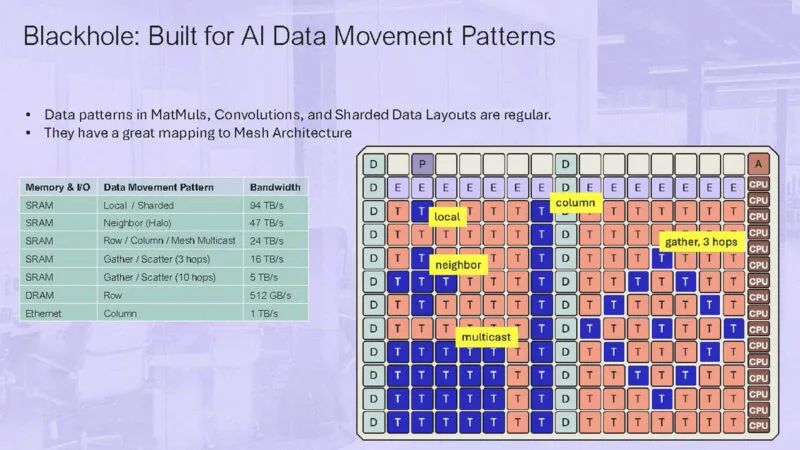
上图显示的是 2×2 的Blackhole 网格。AI 具有大量数据局部性,因此这些网格非常高效。
Blackhole Galaxy 将拥有 32 个芯片,采用 4 x 8 网格拓扑结构。
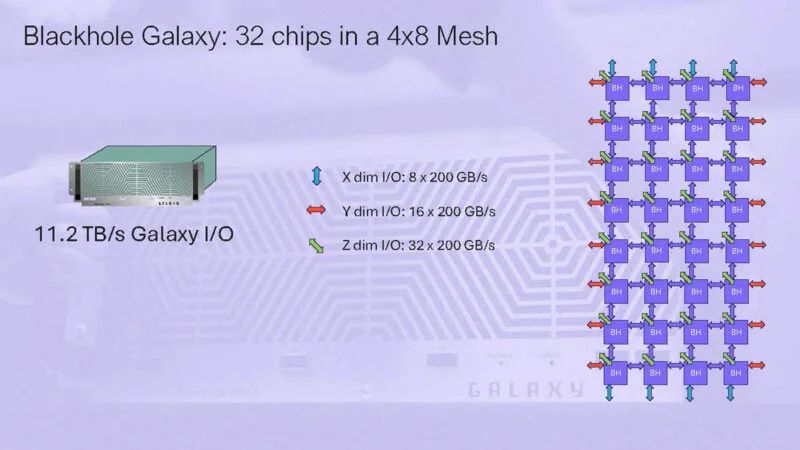
这个想法就是可以通过在网络中添加更多的盒子来实现扩展。
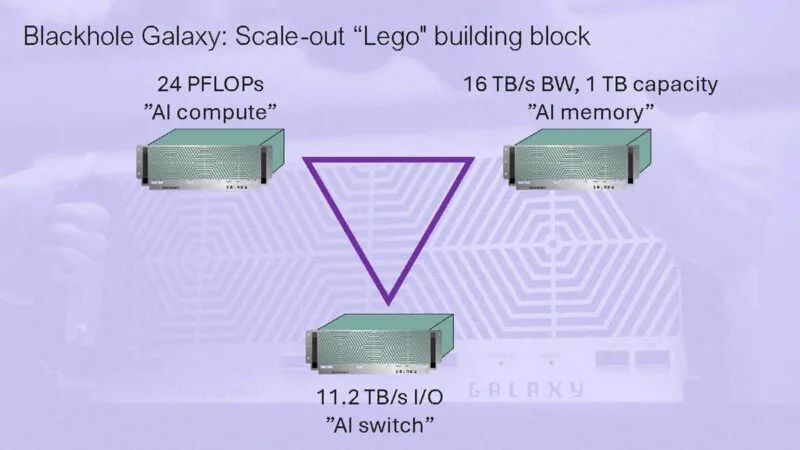
TT-Metalium 是该公司低级编程模型的一部分,旨在将硬件转变为可用于运行 AI 的东西。

以下是关于 Tenstorrent 开源软件的一些信息。
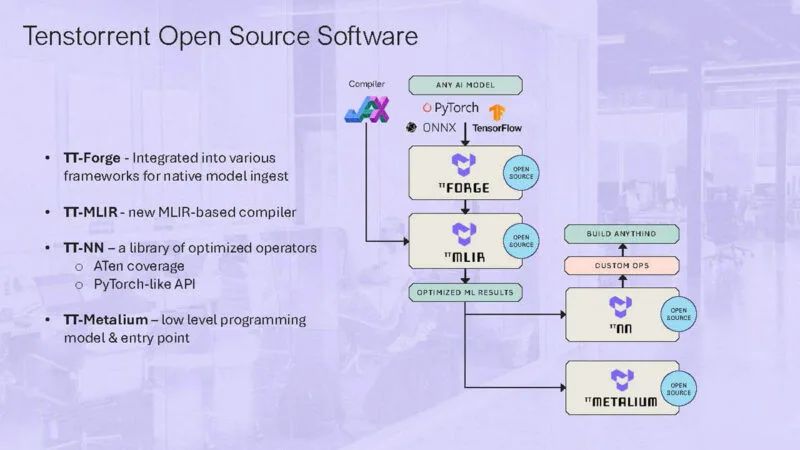
这是关于集成的另一个内容。
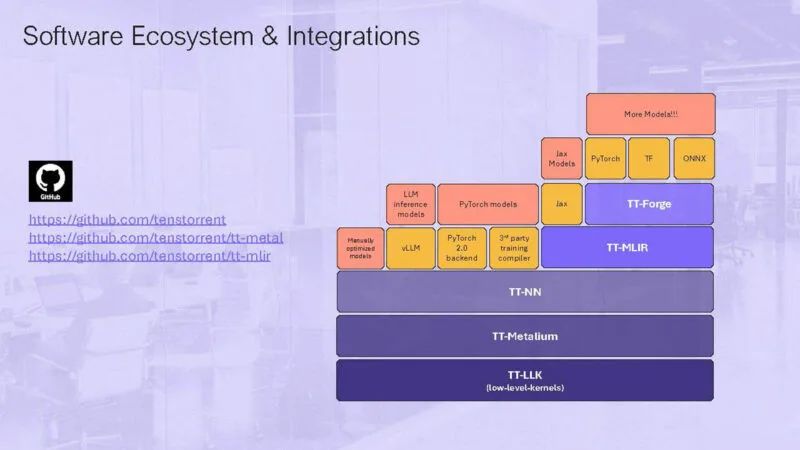
在 RISC-V 和以太网的使用之间,Tenstorrent 正在走向开放系统以加速 AI,这很酷,这也正是为什么 51.2T 以太网将在行业中占据重要地位的原因之一。像 Blackhole 这样的 AI 芯片正在使用高端以太网进行扩展。
高通自研内核深度揭秘
在 Hot Chips 2024 上,高通详细介绍了使用在其骁龙 X Elite 中的 Qualcomm Oryon CPU。
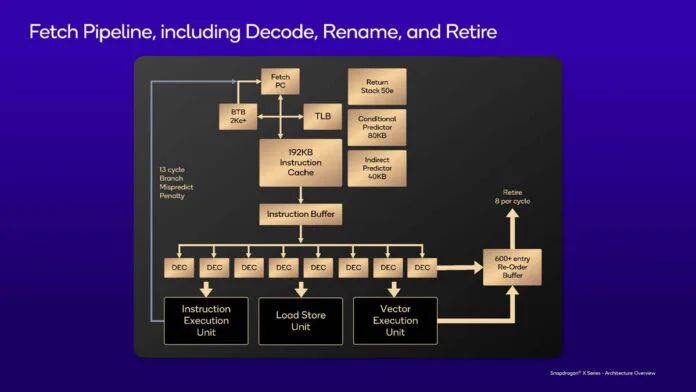
Qualcomm Oryon 是该公司为 Snapdragon X Elite SoC 提供动力的 CPU。这是 Nuvia 团队基于 Arm 的核心。这里的集群是相同的,但出于功率目的,它们的运行方式不同。

高通重点关注的 CPU 核心领域包括指令获取单元 (IFU)、矢量执行单元 (VXU)、重命名和退出单元 (REU)、整数执行单元 (IXU)、内存管理单元 (MMU) 以及加载和存储单元 (LSU)。

以下是 Oryon 的提取和解码规格。13 周期分支预测错误延迟并非业界最佳,但高通表示,该设计已“平衡”。

这是芯片的获取管道。解码后,指令移至 600+ 条目重排序缓冲区。解码器可以处理架构中的每个指令类。
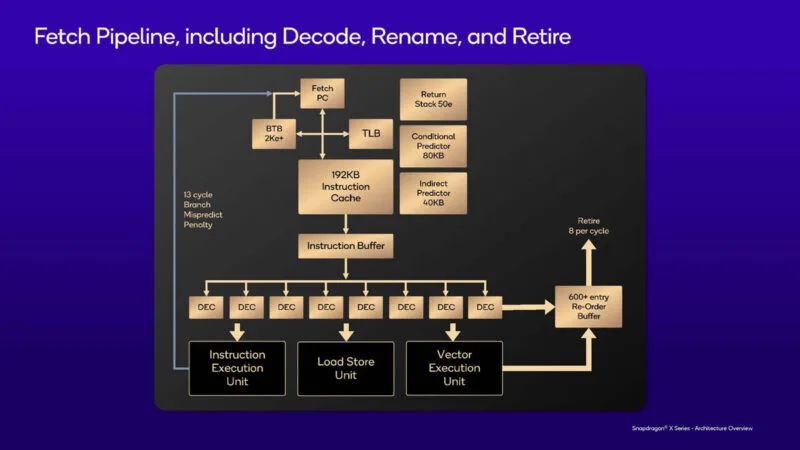
这是重命名调度和执行规范。寄存器文件是大约 400 个条目的物理寄存器文件。整数是 6 宽,向量是 4 宽,加载存储也是 4 宽。每个管道在向量执行管道端是 128 位。它支持几乎所有数据类型。

这是以图片形式呈现的指令执行流水线。所有执行单元中都有 ALU 和移位器。我们还可以看到传输到矢量单元的部分。
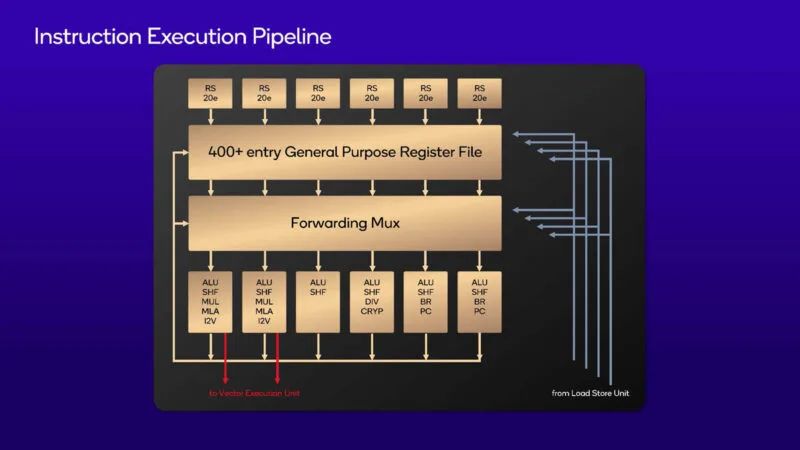
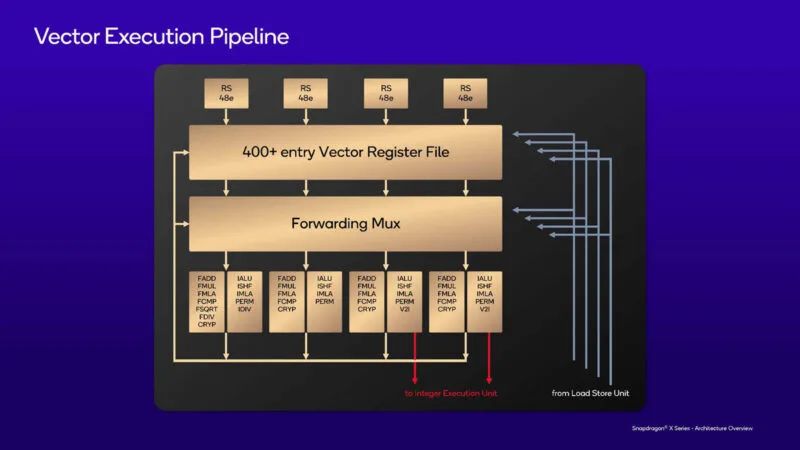
这是向量执行管道。我们还可以看到转移到整数执行端的部分。
以下是加载存储规格。高通在这里使用的是标准的 16 位单元。可以有超过 200 个正在进行的加载存储操作。预取在这里非常重要,因此混合使用了专有预取器和行业预取器。这些预取器应用于缓存和转换结构。

这是内存系统层次结构。有一个相对较大的 L2 缓存。每个保留站有 64 个条目。缓存往往以核心频率运行,延迟较低。平均到 L2 缓存的延迟为 15-20 个时钟。

以下是内存管理单元的规格。幻灯片上没有显示,但每时钟周期内大约有 10-20 个运行中的操作。

这是内存子系统。值得注意的是,系统级缓存相对较小,只有 6MB。6MB 缓存可供 SoC 中的所有引擎使用。
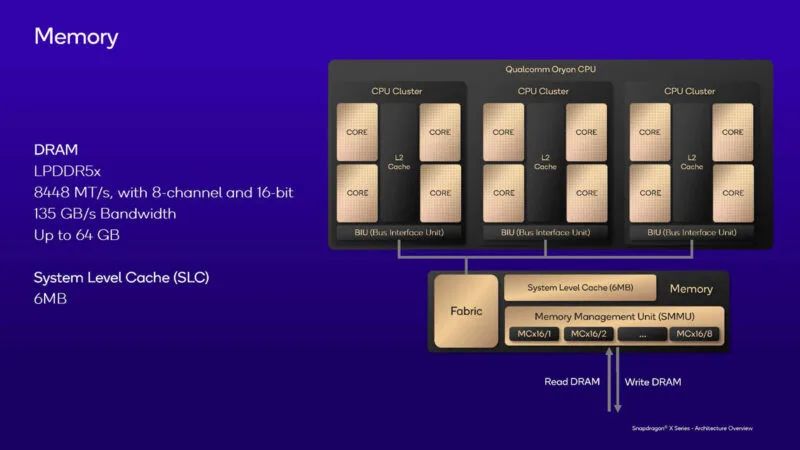
由于这些 SoC 适用于笔记本电脑(很容易被盗或放错),因此它们具有以下一些安全功能。

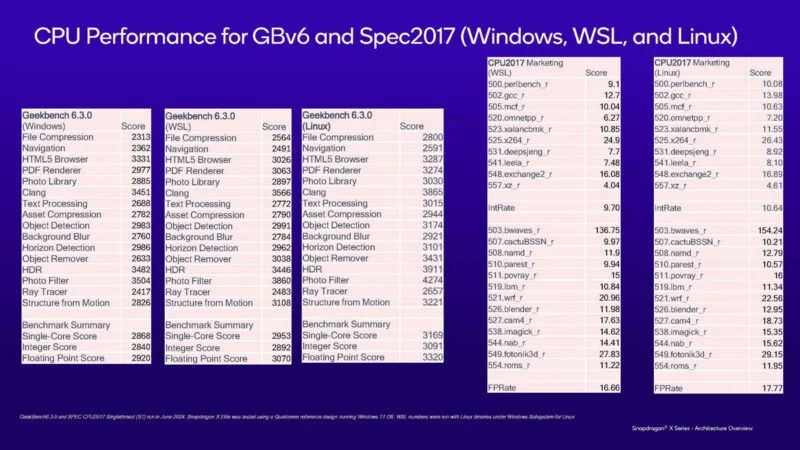
高通的每核性能非常好,与 Arm Neoverse N 系列或 AmpereOne 核心相差甚远。同样有趣的是,Geekbench 6 在 Linux 甚至 Windows Subsystem for Linux 上的表现都比在 Windows 上的表现要好。SPEC CPU2017 结果也显示出同样的情况。
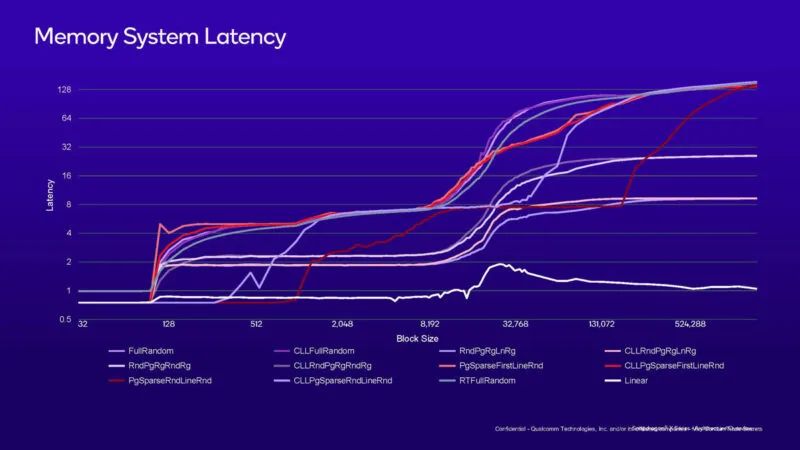
这是内存系统延迟图表。右侧一半以上的较大转变是 12MB L2 缓存延迟转变。
这是使用单线程的内存带宽图表。单核能够以略低于 100GB/s 的范围进行传输,考虑到 LPDDR5x 内存的 135GB/s 平台带宽,这非常了不起。
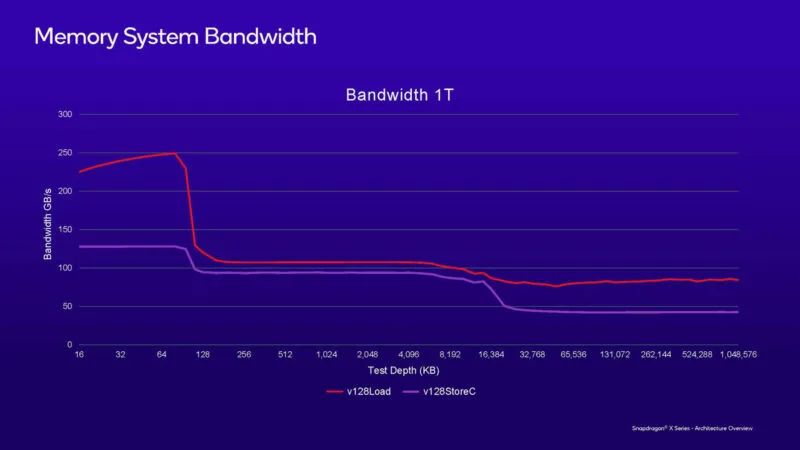
高通希望将 Oryon 的用途拓展到笔记本电脑以外的领域。但从图中我们没有发现服务器领域的应用。

英特尔 Lunar Lake和Granite Rapids-D
在 Hot Chips 2024 上,英特尔则带来了面向AI PC 的Lunar Lake和面向数据中心的最新至强6 SoC Granite Rapids-D。首先看Lunar Lake,这是该公司面向移动设备的下一代 AI PC 部件。与 Meteor Lake 相比,英特尔正在进行大量集成并做出一些重大更改,因此这将是一次重大的世代变革。

英特尔在这里为不同的块使用不同的工艺节点,这正变得越来越普遍。这一代的一大亮点是包含片上内存。这类似于苹果、NVIDIA 等公司的设计,以及一些高端 HPC 处理器,其中内存是集成的,而不是 LPCAMM、SODIMM 或 DIMM 形式。

英特尔只将内存容量提升至 32GB。其中一个挑战是英特尔必须从其他供应商处购买内存,这会降低芯片的利润率。64GB 芯片的利润率将低于 32GB,因为成本越高,DRAM 的利润率就越低。当然,苹果对额外内存收取的费用高得离谱,因此它通过系统的垂直整合获得了巨大的利润。这是一个有趣的领域,我们可以看到行业竞争和财务状况对业绩的影响。

接下来,英特尔开始涉足 SoC 结构,包括芯片和计算块。在这里,我们可以看到四个 P 核心,缓存为 3MB,IPU、GPU、内存子系统等都位于同一芯片上。

Lunar Lake 有一个内存侧缓存。这是一个 8MB 的物理缓存,旨在减少 DRAM 流量。
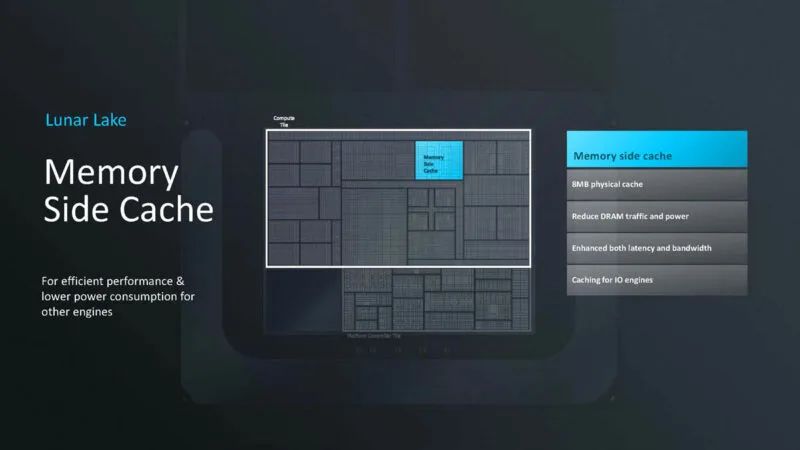
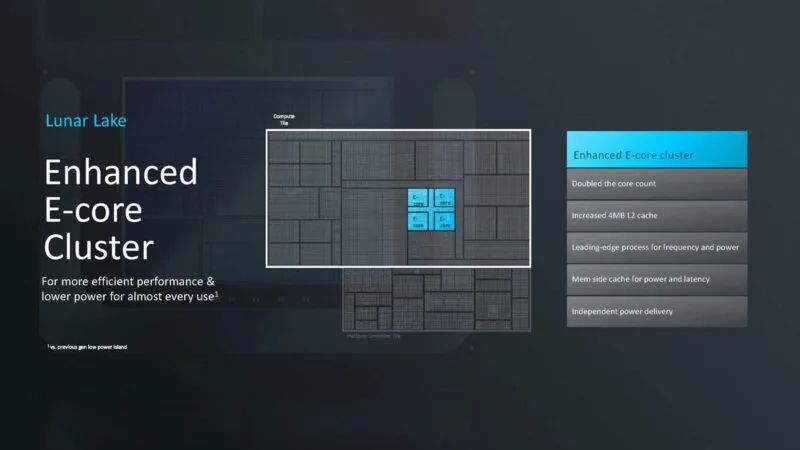
E 核心集群现在具有 4MB 的 L2 缓存、自己的电源传输等等。E 核心不是旧的 Atom 核心。现在它们的速度相当快。这里现在有四个 E 核心,而不是 Meteor Lake 中的两个。这里也使用了内存侧缓存来提高性能。
Lunar Lake 的很大一部分是电源传输和管理。SoC 现在有 4 个 PMIC。据称这些 PMIC 是相同的,但被复制并独立管理。

这些 PMIC 有助于优化 SoC 的供电和效率。E 核心集群旨在处理当今大多数工作负载,因为它们的速度越来越快。英特尔还表示,进入和退出睡眠状态的速度要快得多。

英特尔仍然拥有线程控制器等功能以及工作负载分类,以便将工作负载放在正确的核心资源上。
Lion Cove P-Core 是一个重大变化。这感觉就像是英特尔长期以来最大的变化之一,如果不是最大的变化的话。

英特尔表示,新的设计数据库已经过现代化升级,有助于过渡到不同的流程以及不同的设计和功率范围。以下是 Lion Cove 的亮点。英特尔表示,它们已经进行了性能和效率优化。最大的变化可能是 SMT 或超线程已被删除。

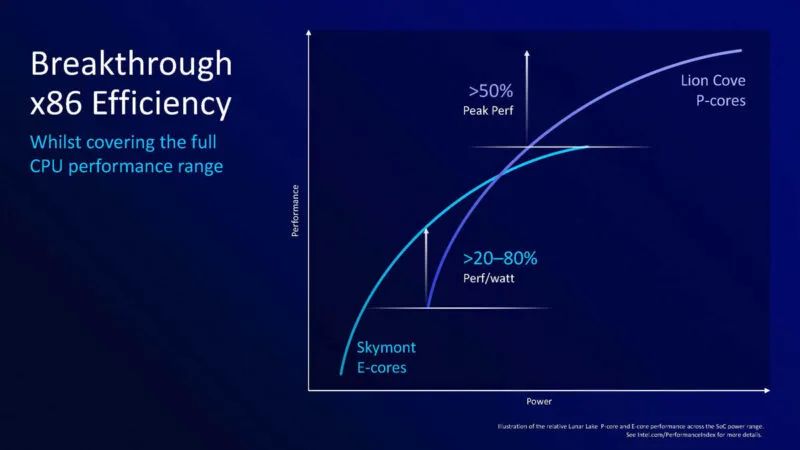
英特尔表示,新核心在 IPC 基础上的性能提升了约 14%。这一点很重要,因为时钟速度可能有所不同。它还表示,与上一代相比,它可以提供两位数的每瓦性能。
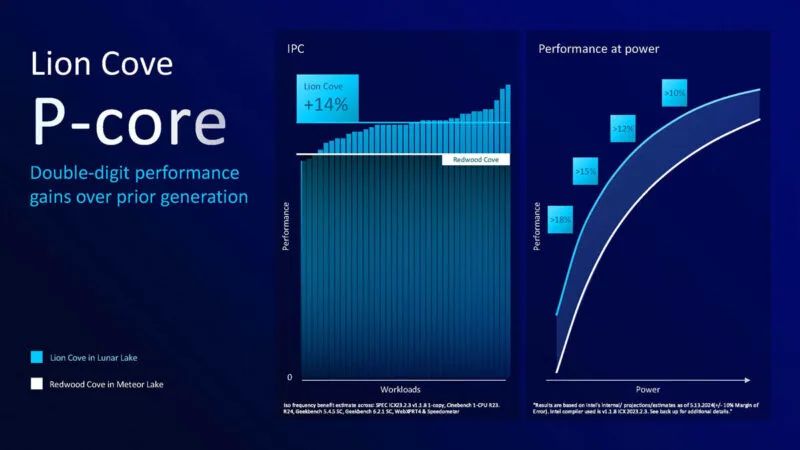
英特尔正在对低功率范围进行大量优化。英特尔表示,删除超线程有助于他们在低功耗下提高效率。
我们还有 Skymont E-core,旨在承担更多的工作负载。
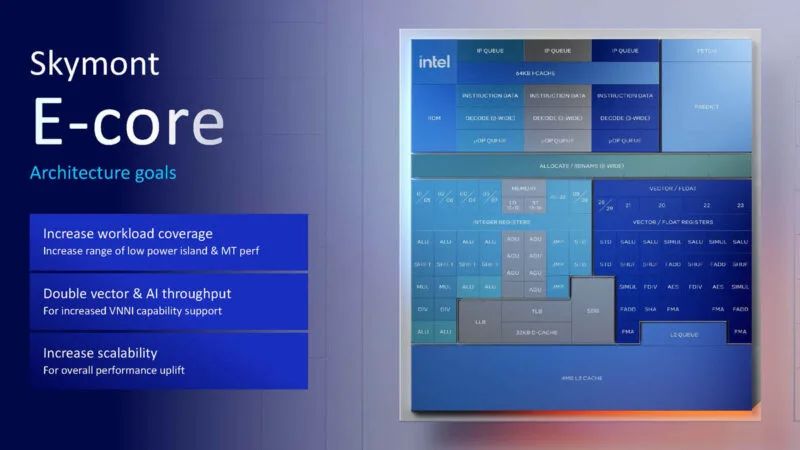 以下是 Skymont 的亮点:
以下是 Skymont 的亮点:

在低功耗岛上,Lunar Lake 到 Meteor Lake 的差异非常大。英特尔表示,这不仅包括微架构,还包括缓存、系统延迟等,因此这不仅仅是微架构的直接提升。
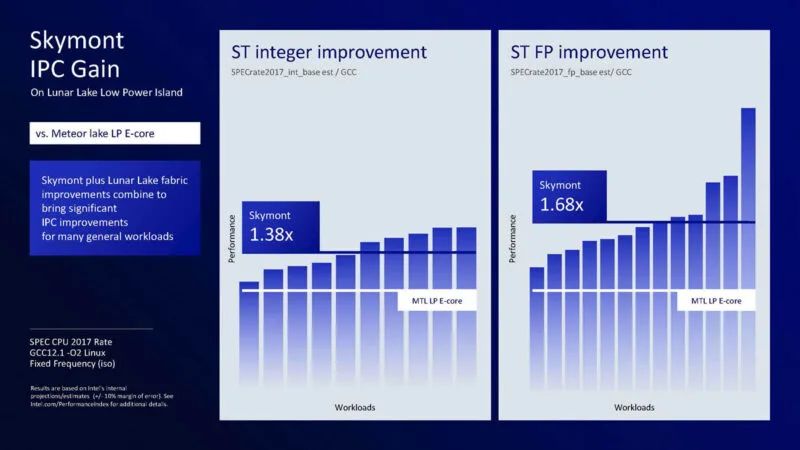
这是新低功耗岛 E 核的每瓦性能或功率图性能。需要注意的是,电源线比 Meteor Lake 的更长。
 以下是 Lunar Lake 和 Meteor Lake 核心不同部分的延迟情况。
以下是 Lunar Lake 和 Meteor Lake 核心不同部分的延迟情况。
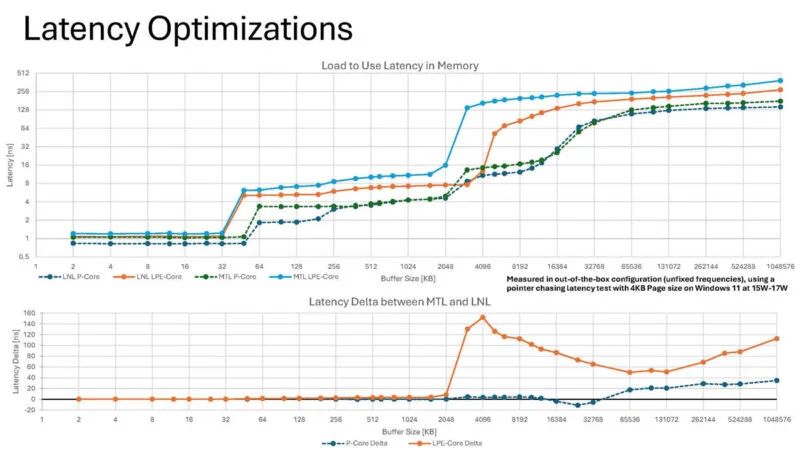 这是核心到核心的延迟情况。这些延迟比我们在最近几代服务器芯片中看到的要好。
这是核心到核心的延迟情况。这些延迟比我们在最近几代服务器芯片中看到的要好。
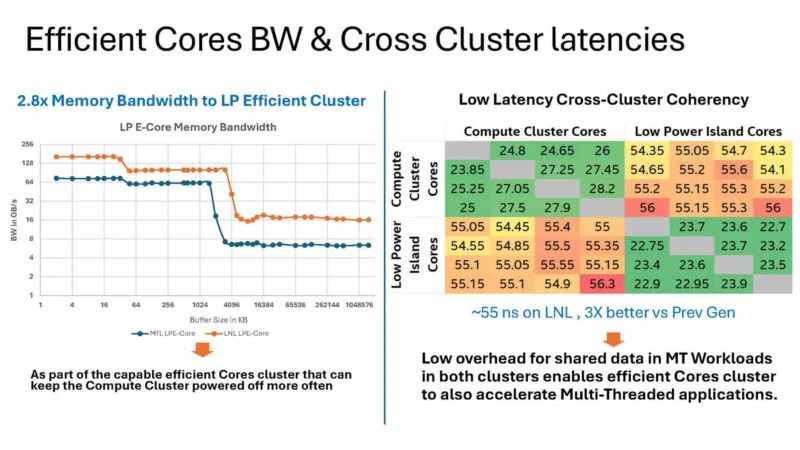 这是 Lunar Lake 中 E 核和 P 核的两条曲线。
这是 Lunar Lake 中 E 核和 P 核的两条曲线。
这是 Microsoft Teams 的使用示例。Teams 需要转至 Meteor Lake 上的 P 核心。
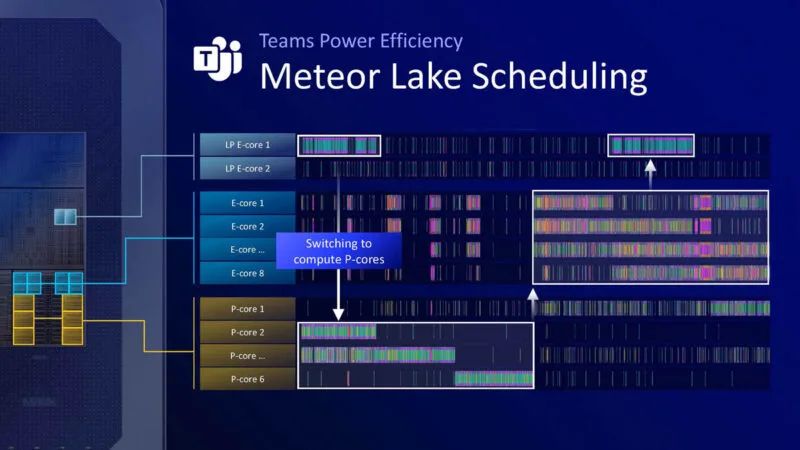 在 Lunar Lake 上,英特尔认为它可以将所有内容保留在 E 核上。
在 Lunar Lake 上,英特尔认为它可以将所有内容保留在 E 核上。
 英特尔表示,其新 GPU 架构 Xe2 将用于客户端 SoC iGPU 以及 dGPU 设计。
英特尔表示,其新 GPU 架构 Xe2 将用于客户端 SoC iGPU 以及 dGPU 设计。
 Xe2 核心的核心是矢量引擎。它已从两个 SIMD8 结构转变为单个 SIMD16 结构。
Xe2 核心的核心是矢量引擎。它已从两个 SIMD8 结构转变为单个 SIMD16 结构。

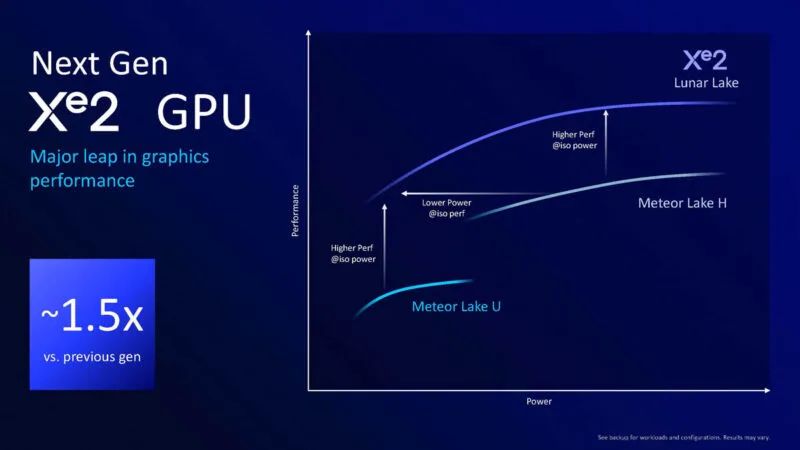
以下是有关新款 Xe2 GPU 的摘要,据称在相同功率下游戏性能可提高 1.5 倍。

这是英特尔的性能效率曲线。一个关键的变化是从低端扩展到高端。Meteor Lake U 和 Meteor Lake H 必须使用不同的引擎,但新的 Xe2 可以覆盖整个范围。
英特尔展示了 Lunar Lake 与 Meteor Lake 的Stable Diffusion演示。

媒体方面,增加了h266。

英特尔表示,采用新媒体引擎后,VVC 解码速度会低得多。

NPU 是热门话题。在这一代中,NPU 变得更大,时钟速度也更高。

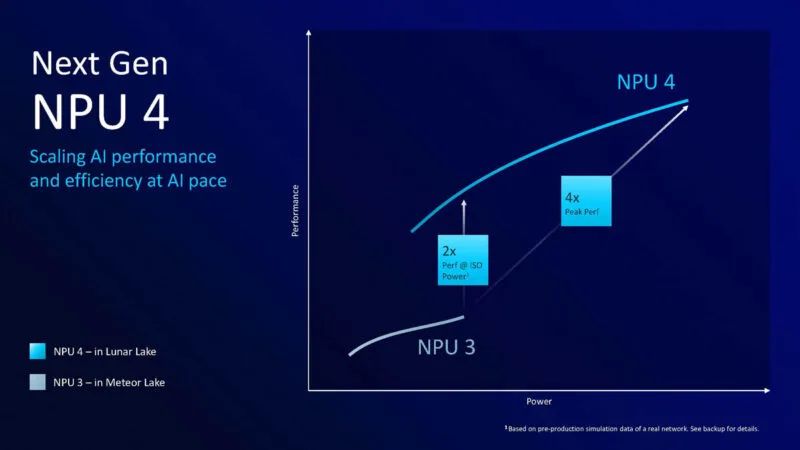
以下是英特尔 NPU 4 的要点。它已从 2 个神经计算引擎增加到 6 个。英特尔表示,仅 NPU 上的计算能力就达到了 48 TOPS。

以下是新 NPU 的性能。注意:NPU 4 的设计还使其在峰值时消耗更多电量。
这是具有 WiFi 7 及更高版本的连接幻灯片。

这是新平台的摘要幻灯片。

接下来,我们看一下面向边缘的英特尔至强 6 SoC Granite Rapids-D。英特尔表示, Xeon D 系列不会采用第四代/第五代 Xeon Sapphire Rapids/Emerald Rapids 的内核,而是会在 2025 年通过 Granite Rapids-D 部件获得 Xeon 6 处理。
Intel Xeon D 系列专为边缘而设计,专门为边缘带来性能核心和集成网络与加速。它介于采用 E 核心的 Atom 系列和主流 Xeon 系列之间。边缘也有所不同,因为它需要不同的工作温度和环境配置文件。

新芯片具有 PCIe Gen5(高于 Ice Lake-D 中的 PCIe Gen4)以及新功能。

以下是亮点,该芯片有 4 通道和 8 通道设计,可以使用高速 MCRDIMM。有 100GbE 连接、Intel QuickAssist、DLB、DSA 和 vRAN Boost。I/O 看起来也非常有趣,最多支持 32 条 PCIe Gen5 通道和 CXL 2.0。

英特尔表示,它拥有更多内核、更多带宽和更多 I/O。

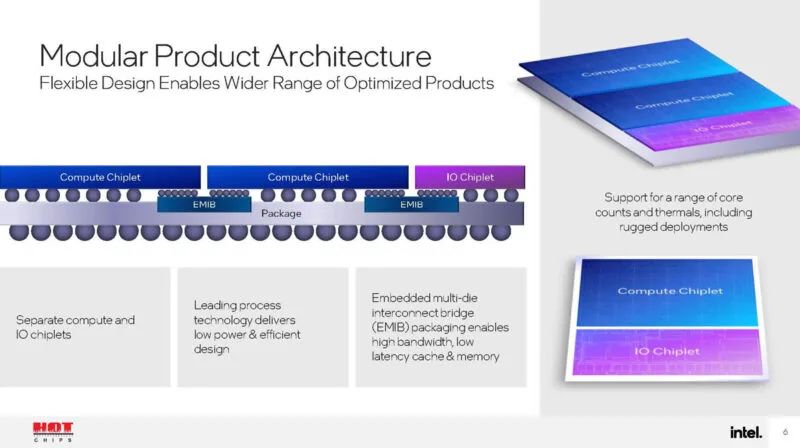
这里最大的变化是英特尔完全转向下一代 Xeon-D 封装。
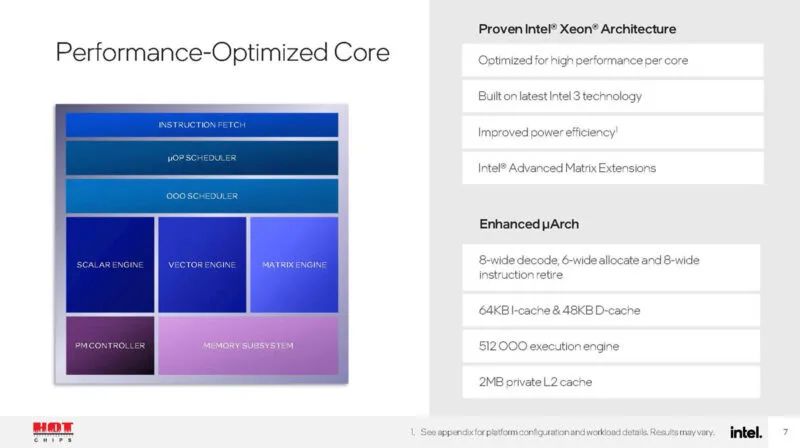
性能核心是 Granite Rapids / Redwood Cove P 核心。值得注意的是,不是英特尔 Lunar Lake P 核心。
新芯片支持 AMX 实现 AI 加速。如果您习惯使用高端 Xeon,这可能看起来不是什么大问题,但如果您之前使用的是仅配备 VNNI 的 Ice Lake-D,那么 AI 性能将获得巨大飞跃。

这是使用 EMIB 拼接在一起的统一缓存和内存。

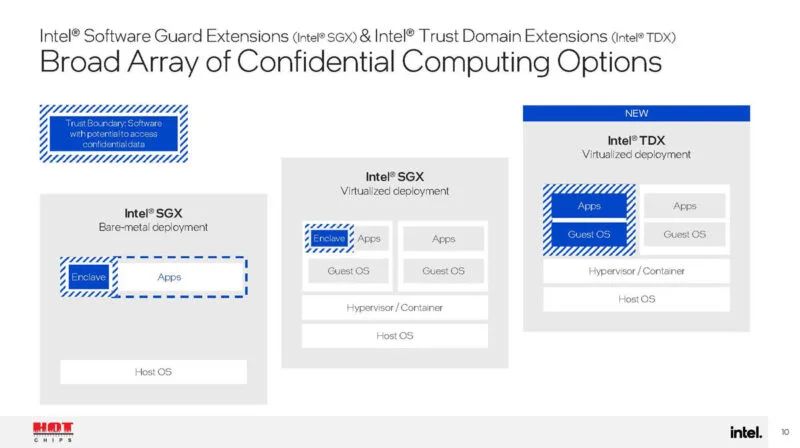
我们还获得了 Intel SGX 和 TDX 用于机密计算。
新的 I/O 芯片组基于intel 4工艺。在这里,我们可以看到各种加速器,包括 DSA、DLB 和 QAT。了解有关媒体加速器的更多信息将会很有趣。英特尔表示它用于 AI 推理和转码。

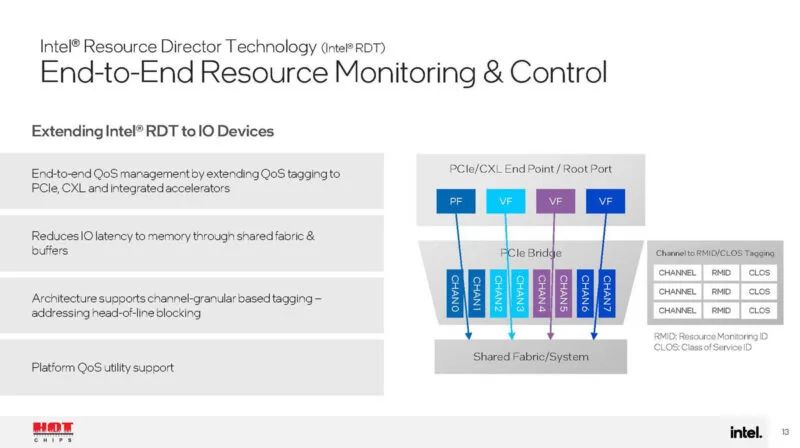
新芯片采用英特尔资源调配器技术,可帮助实现平台上的 QoS 等功能。
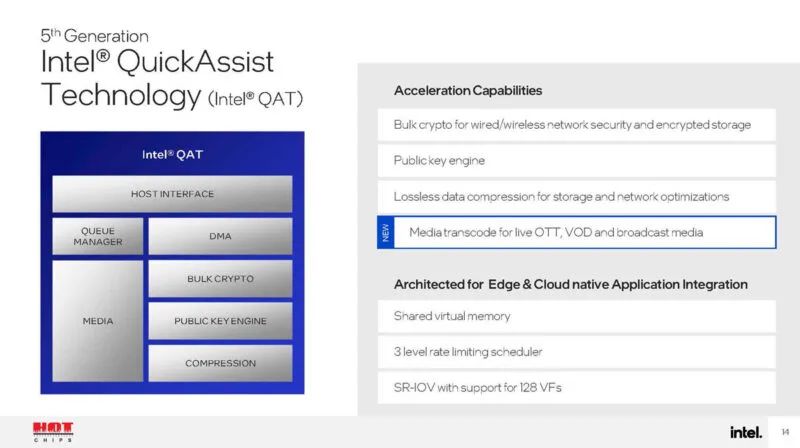
这里还有更多关于 QAT 的信息,包括媒体转码!这真的很棒,因为它将扩展 QAT 的使用案例,而不仅仅是压缩和加密。
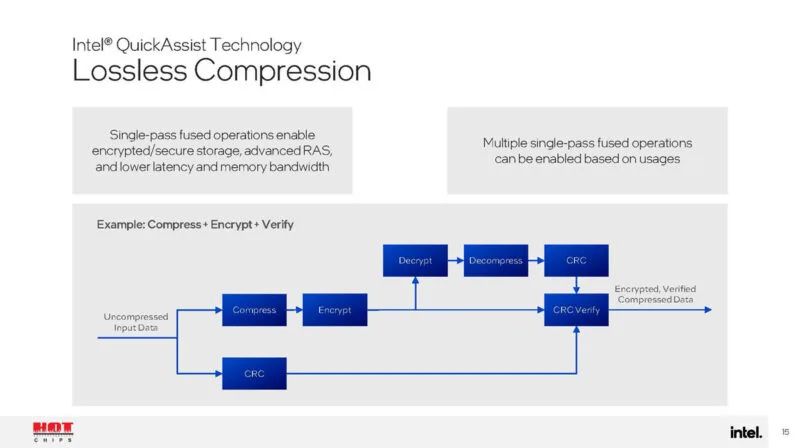
英特尔 QAT 有助于压缩。这是一种单次、经过验证的压缩,可确保压缩过程中不会丢失保真度。这是这一代的新功能。
开始吧。看起来至少有 1080p30 AVC、HEVC 和 AV1 编码、解码、缩放和裁剪。可以使用硬件卸载解码视频,然后用于 AI 推理。这是一项非常重要的功能。
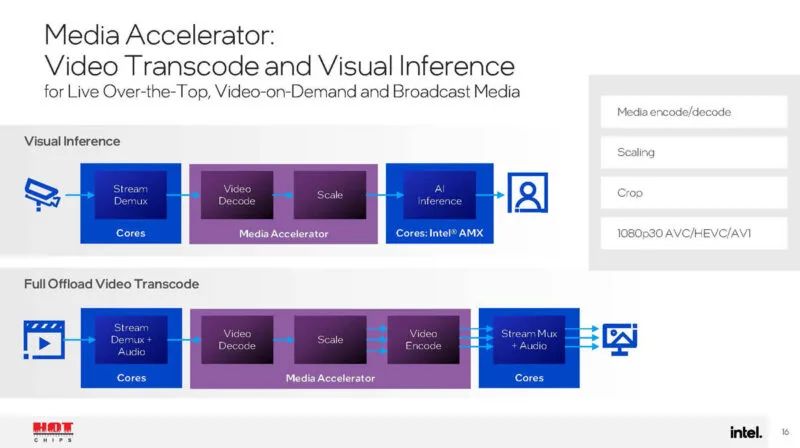
英特尔正在为其 100GbE 网络添加功能。该公司表示,移除 PCIe 可降低功耗需求,但它也将允许其运行自定义解析,以便客户可以对网络进行编程。这是一项新功能。

这里有一些很酷的东西:我们可以看到每个插槽 4 通道内存 2 个 DIMM 设计以及 SoC 的 8 通道内存设计。

这看起来像是 Xeon D-line 的一次重大更新。
与前几代产品相比,这款平台的性能导向非常出色。同时,Atom 系列和 Xeon 6 SoC 之间似乎存在很大差距。Atom P5000/C5000 系列似乎需要更新,配备更现代的 E 核心。即便如此,基础网络似乎正在变成 100GbE,为 10GbE/25GbE 解决方案留下空白。英特尔也似乎看到了 AMD Siena 并正在向高端市场迈进。
AMD Instinct MI300X 架构亮相
在 Hot Chips 2024上,AMD再次介绍了Instinct MI300X 架构。

MI300A 主要用于 HPE El Capitan 等超级计算机。MI300X 似乎是该系列今年 40 亿美元收入的主要推动力。
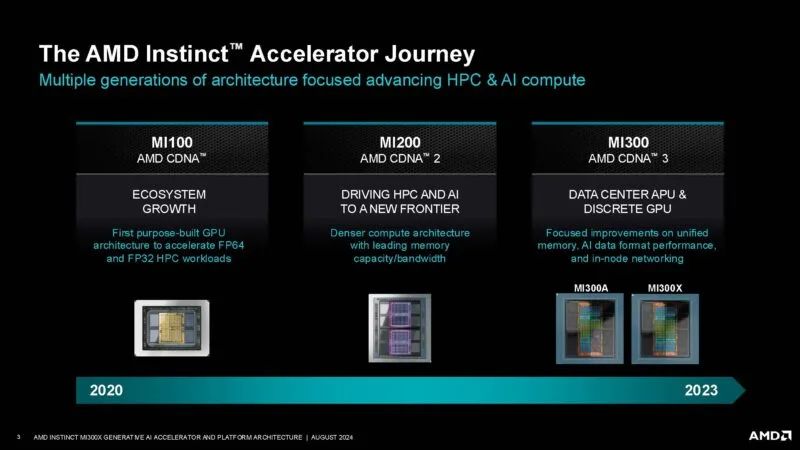
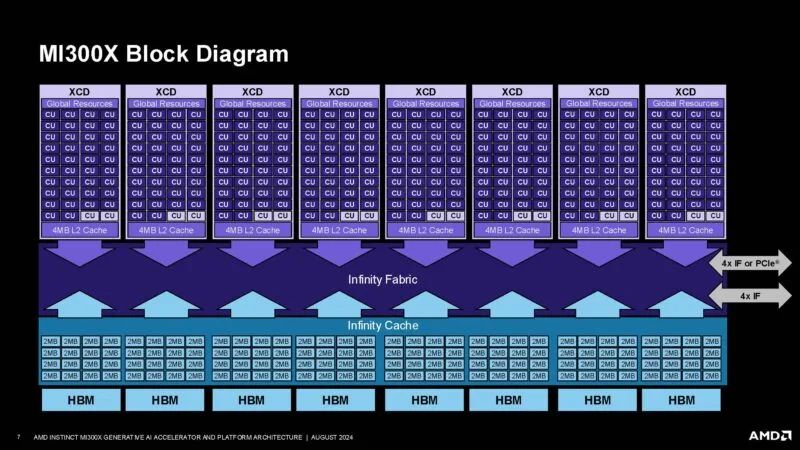
AMD 拥有一款相当复杂的芯片,具有 192MB 的 HBM3、用于计算的芯片等等。

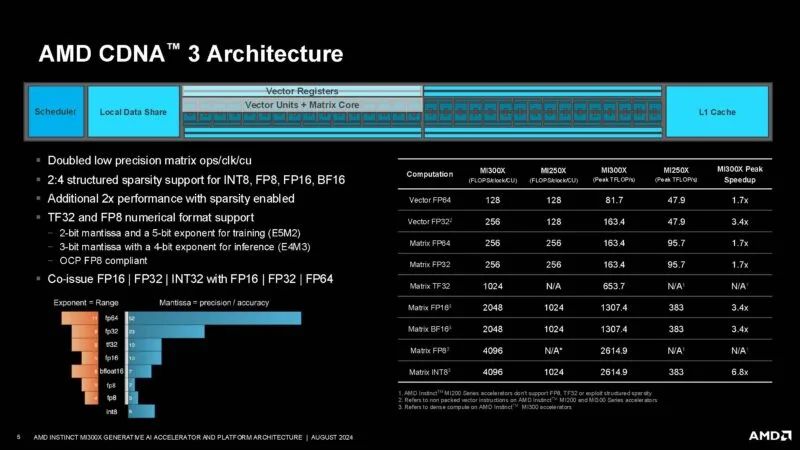
以下是 AMD CDNA 3 架构的演变。
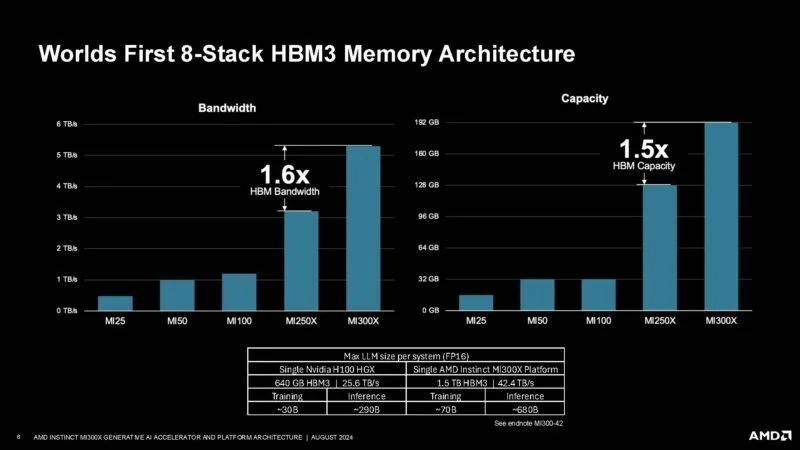
AMD 拥有一个 8 堆栈 HBM3 内存阵列,容量高达 192GB,在当时相当巨大。
这是包含用于计算的 XCD 以及 Infinity Cache、Infinity Fabric 和八个 HBM 封装的框图。
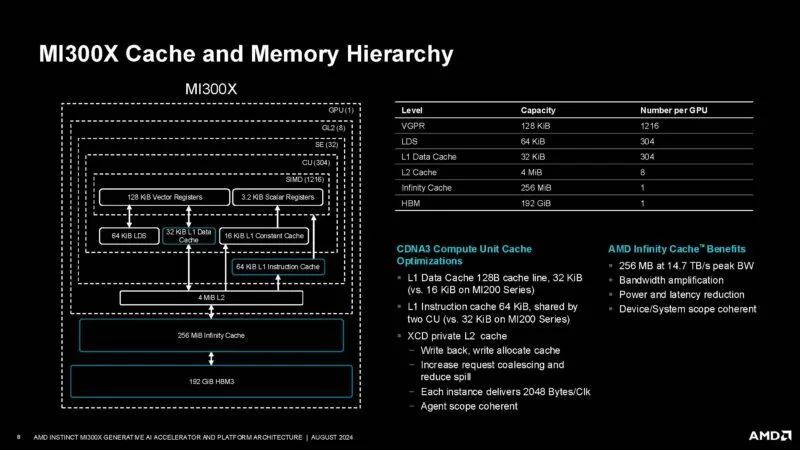
以下是缓存和内存层次结构。我们不仅可以看到 192GB 的 HBM3,还可以看到 256MB 的 Infinity 缓存、8x 4MB 的 L2 缓存等等。
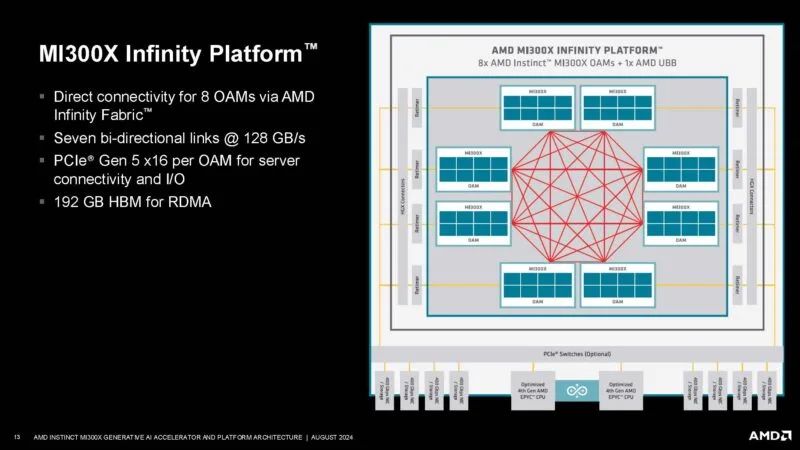
MI300X 可以作为单个分区运行,也可以在不同的内存和计算分区中运行。

AMD的大平台目前是8路的MI300X OAM平台。

这是 Instinct 系统之旅。MI200 也采用了 OAM 板,但此处显示为单个 GPU。

每个 GPU 有七个用于直接连接的链路和主机链路。
在今天的 OpenAI 演讲之后,RAS 在大规模 AI 集群中变得非常重要。
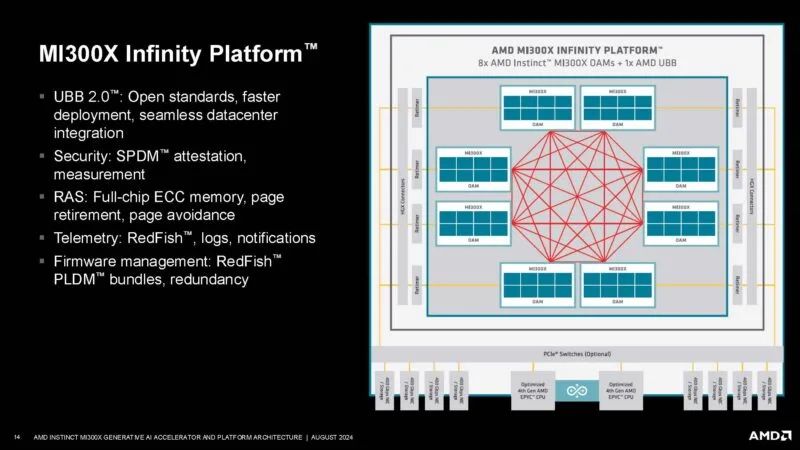
这是 AMD 的服务器。微软/ZT System 的 MI300 平台没有在这里被提及。戴尔仍然没有在其 AI 平台上提供 EPYC,这有点令人失望。同样值得注意的是,Wiwynn 平台也缺席了。

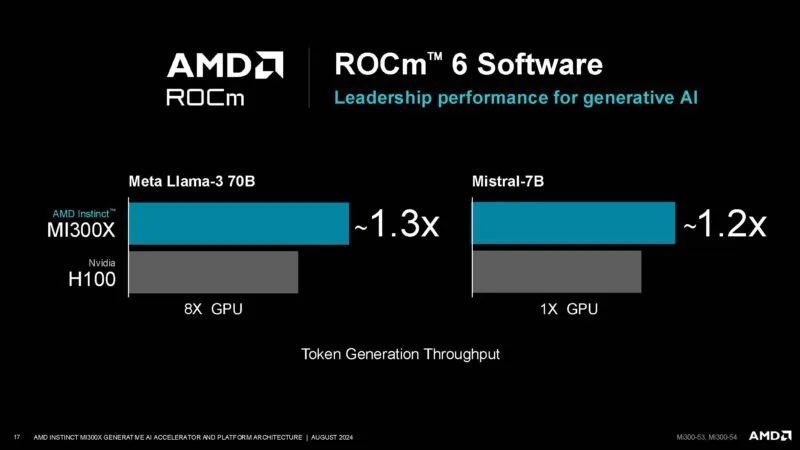
AMD 正在谈论 ROCm,它正在变得越来越好。

在某些情况下,AMD 可以击败 NVIDIA H100。当然,我们预计人们会开始更频繁地部署 NVIDIA H200,特别是如果他们可以使用液冷并且 B100/B200 即将推出的话。在 AMD 方面,AMD 也致力于 MI325X。因此,这需要考虑到时间背景。
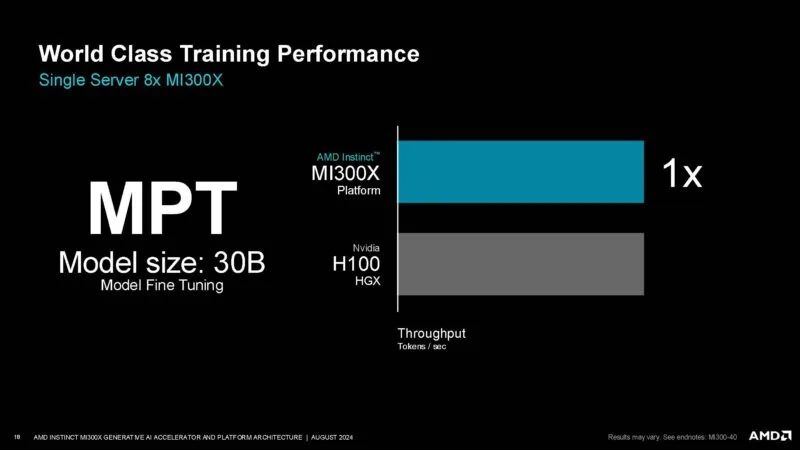
这是 MPT 微调,AMD 称其与 H100 相当。
人工智能训练和推理的英特尔 Gaudi 3
直到 Falcon Shores,英特尔的主要 AI 芯片都是英特尔 Gaudi 3。我们在 Hot Chips 2024 上获得了一些新的细节。这是自 2019 年左右以来的第三代 Gaudi。这一代增加了更多的计算能力、更多的内存带宽和容量。
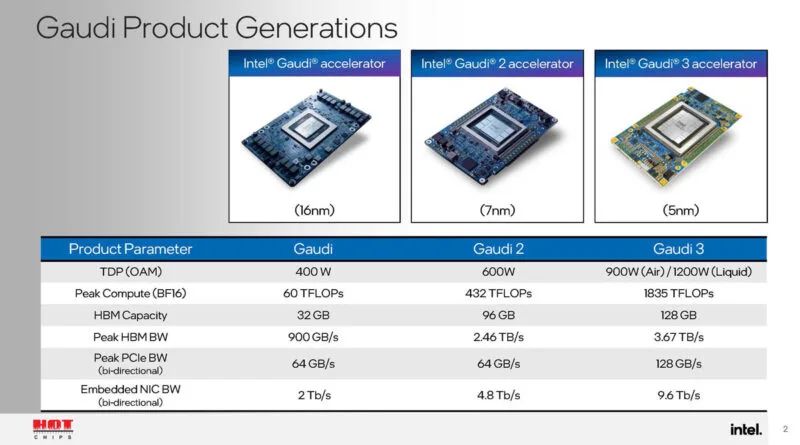
这是 OAM 模块。两个互连的计算芯片互为镜像。
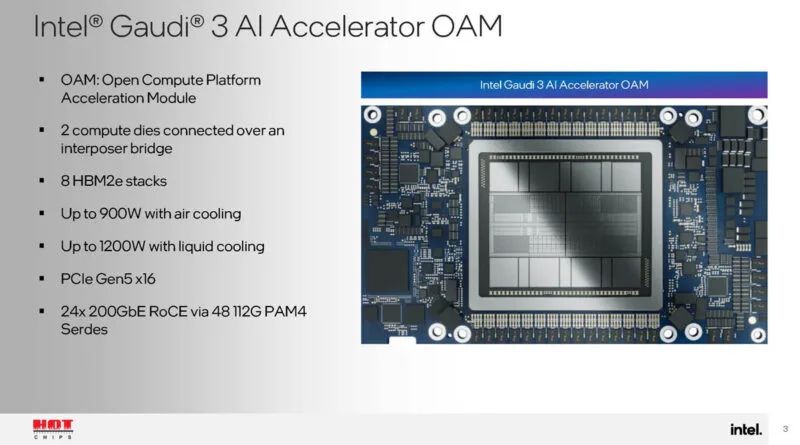
这是框图。这里非常有趣的是,有 14 个解码器用于 HEVC、H264、JPEG 和 VP9。这对于视频推理很重要。我们还获得了很多速度和反馈。
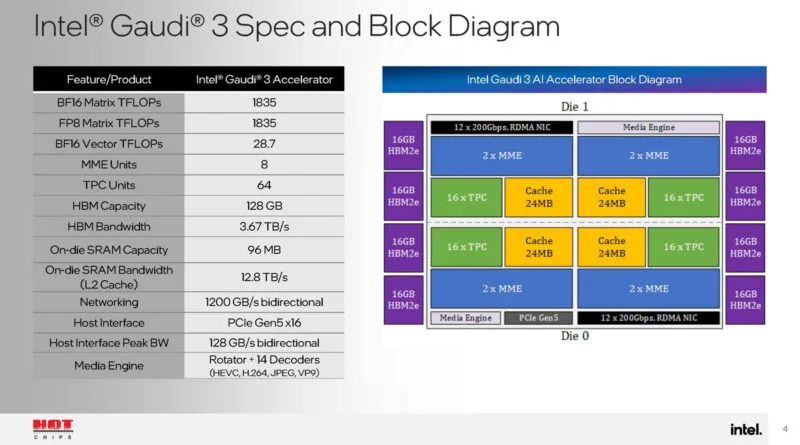
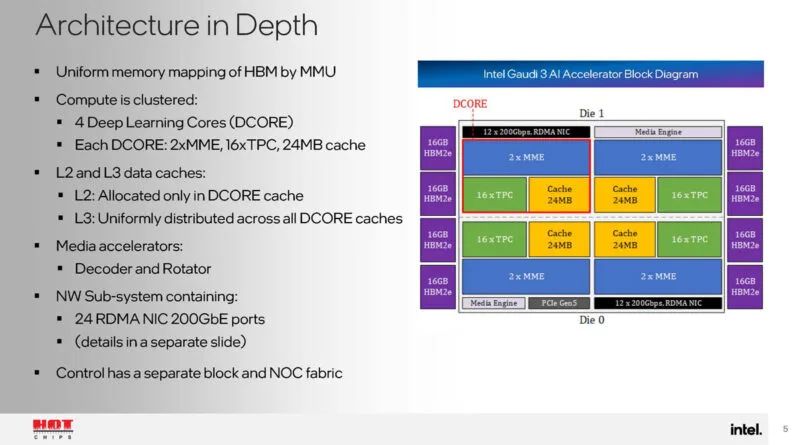
每个芯片有两个 DCORE 或深度学习核心。每个芯片都有一对矩阵乘法引擎、十六个张量处理器核心以及 24MB 缓存。
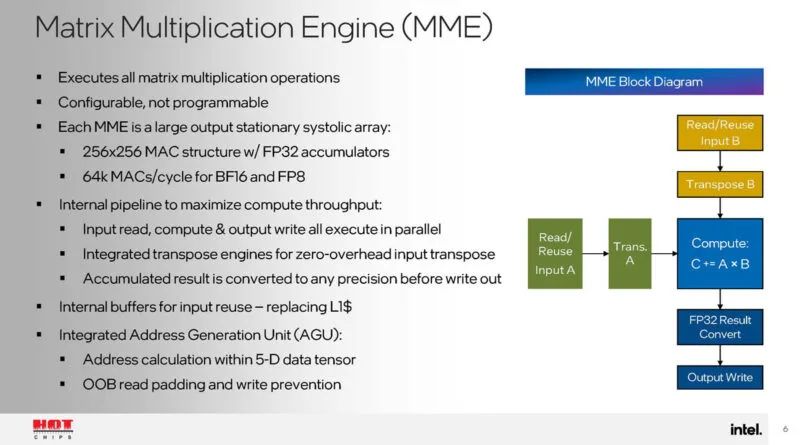
矩阵乘法引擎是Gaudi 3加速器的大矩阵计算引擎。
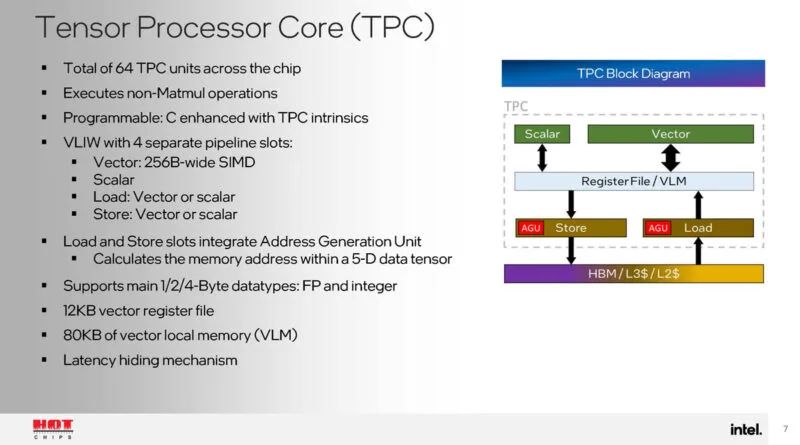
张量处理器用于非 Matmul 计算。
L2、L3 和 HBM 都位于统一的内存空间中。还有一个内存上下文 ID,允许标记共享的缓存行。还有一个近内存计算功能,可以为 TPC 节省一些工作。
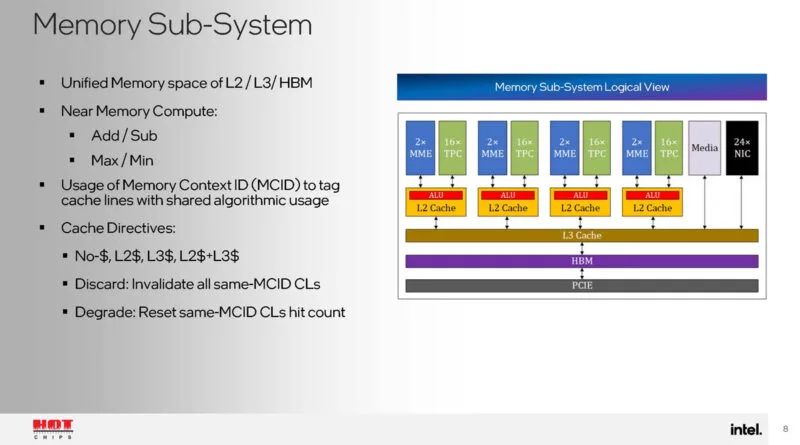
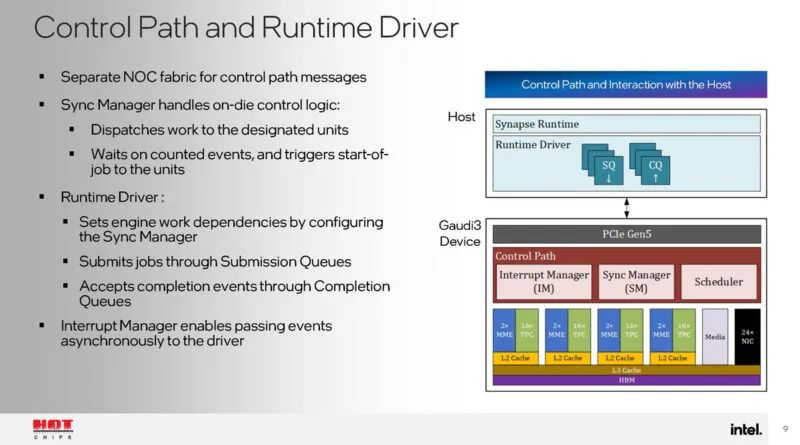
Gaudi 3 还具有独特的控制路径和运行时驱动程序。
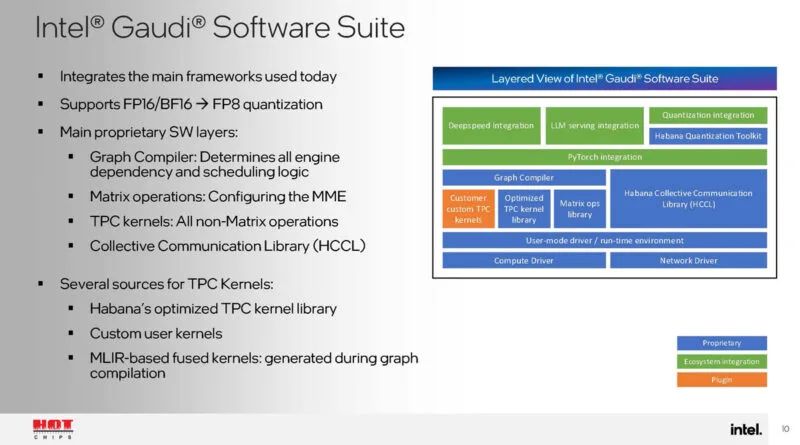
以下是关于英特尔 Gaudi 软件套件的一些信息。我有点希望英特尔能更进一步,只谈论 Falcon Shores 的 Gaudi 套件。如果 Falcon Shores 是 2025 年,感觉这应该是讨论的一部分。
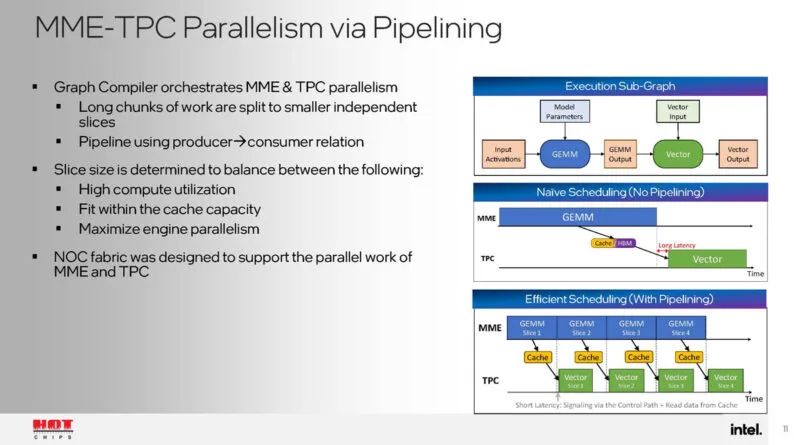
图形编译器负责协调加速器之间的工作分配。NOC 带宽旨在支持并行 MME 和 TPC 工作。
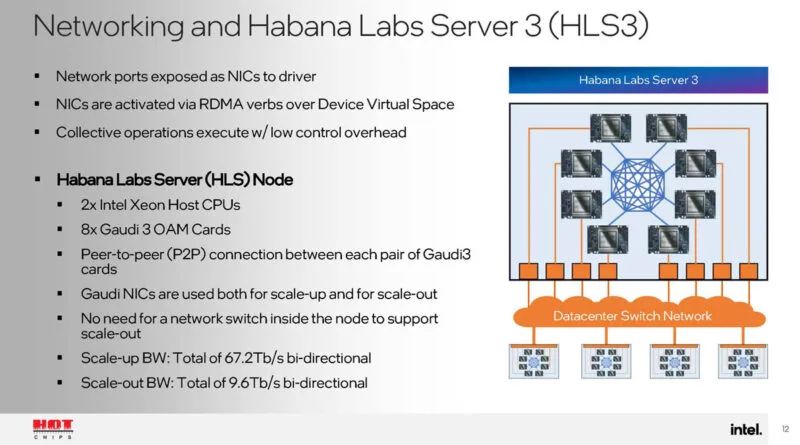
这是 Habana Labs 做的很酷的事情之一,我们在 2019 年Hot Chips 31上看到他们,当时 Hot Chips 最后一次在斯坦福纪念剧院举行。Habana 使用来自加速器的 RDMA 以太网网络将每个加速器相互连接,然后连接到更大的拓扑。
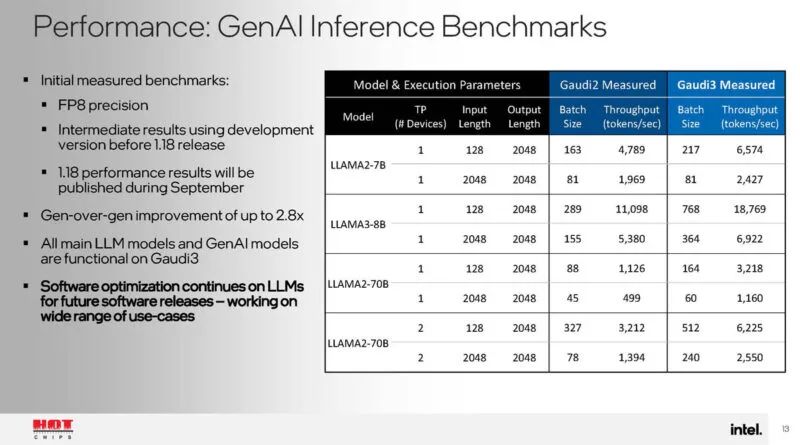
以下是一些性能基准。扩展正在进行,但看起来 Llama3-8B 仍在优化中。
借助以太网网络,Gaudi 3 可以使用标准网络轻松扩展。

同时,问题在于它是否“具有任何规模”,或者他们是否已经像在高端系统上一样对 65,000 或 100,000 多个加速器进行了实际测试。
这款芯片正在加速生产,所以我们很快就会看到更多。去年我们在英特尔开发者云上展示了 Gaudi 2,今年早些时候我们首次展示了Gaudi 3 UBB。
后续详见HotChips2024(2)
文章转载自公众号半导体行业观察 编辑部
原文链接:https://mp.weixin.qq.com/s/GHJFcDUSwXw0BVGZk4smDw